




El siguiente artículo ha sido revisado y verificado por Juliana Diaz, Ingeniera Senior de Software (Analítica de Datos y Visualización) en EPAM Anywhere. ¡Muchas gracias, Juliana!
¿Estás buscando obtener un puesto como ingeniero de datos? La preparación es clave, y eso comienza con familiarizarte con las preguntas comunes de entrevistas técnicas. En este artículo, hemos compilado una lista de 12 preguntas esenciales para entrevistas de ingenieros de datos, junto con sus respuestas, para ayudarte a destacar en tu próxima entrevista.
Desde la integración y procesamiento de datos hasta las tecnologías basadas en la nube y la gobernanza de datos, estas preguntas cubren diversos temas, desde las preguntas básicas para entrevistas de ingenieros de datos hasta las más avanzadas para evaluar tus habilidades técnicas y tu capacidad para resolver problemas. Ya seas un ingeniero de datos experimentado o estés comenzando tu carrera, dominar estas preguntas de entrevista aumentará tu confianza y aumentará tus posibilidades de éxito en el competitivo campo de la ingeniería de datos.
aplica un trabajo de ingeniero de datos en EPAM Anywhere
No necesitas buscar más publicaciones de trabajo. Envíanos tu currículum y nuestros reclutadores se pondrán en contacto contigo con el mejor trabajo que coincida contigo.
1. Describe la experiencia en el diseño y desarrollo de tuberías de datos.
Preguntas básicas de entrevistas para ingenieros de datos como esta son un excelente punto de partida para evaluar la familiaridad de un candidato con los principios esenciales de la ingeniería de datos y su capacidad para aplicarlos en escenarios prácticos.
El diseño y desarrollo de tuberías de datos son fundamentales en la función de un ingeniero de datos. Implica la recolección, transformación y carga de datos desde diversas fuentes hacia un destino donde se puedan analizar y utilizar de manera efectiva. A continuación, se detallan los componentes clave involucrados en este proceso:
- Identificación de la fuente de datos: Es fundamental comprender las fuentes de datos y sus formatos. Esto puede incluir bases de datos, APIs, archivos de registro o fuentes de datos externas.
- Extracción de datos: Extraer datos de las fuentes identificadas utilizando métodos de extracción apropiados, como consultas SQL, web scraping o llamadas a APIs.
- Transformación de datos: Aplicar transformaciones a los datos extraídos para asegurarse de que estén en un formato consistente, limpio y utilizable. Esto puede implicar limpieza de datos, normalización, agregación o enriquecimiento.
- Carga de datos: Cargar los datos transformados en un sistema de destino, que puede ser un almacén de datos, un lago de datos o una base de datos analítica específica.
- Orquestación de la tubería: Gestionar el flujo general y la ejecución de la tubería de datos. Esto puede incluir la programación de trabajos, el monitoreo de la calidad de los datos, el manejo de situaciones de error y asegurar la consistencia y confiabilidad de los datos.
- Escalabilidad y optimización de rendimiento: Diseñar la tubería para manejar grandes volúmenes de datos de manera eficiente y optimizar el rendimiento a través del procesamiento paralelo, la partición y la indexación.
- Calidad de datos y monitoreo: Implementar medidas para garantizar la calidad de los datos, incluyendo la validación de datos, la detección de anomalías y el manejo de errores. También es crucial monitorear la tubería en busca de fallos, problemas de latencia u otras anomalías.
- Mantenimiento e iteración: Revisar y actualizar regularmente la tubería de datos para adaptarla a cambios en las fuentes de datos, requisitos empresariales y tecnologías emergentes. Esto incluye incorporar retroalimentación, realizar mejoras y solucionar problemas.
La experiencia de un ingeniero de datos en el diseño y desarrollo de tuberías de datos abarca una comprensión profunda de la integración de datos, el modelado de datos, la gobernanza de datos y las herramientas y tecnologías involucradas, como marcos de trabajo ETL, programadores de flujos de trabajo y plataformas en la nube. Además, la familiaridad con lenguajes de programación como Python y SQL, y el conocimiento de marcos de trabajo de cómputo distribuido como Apache Spark, pueden contribuir significativamente a la construcción de tuberías de datos eficientes y escalables.

2. ¿Cómo integra datos de múltiples fuentes?
Aquí hay algunos pasos clave y consideraciones para integrar datos de manera efectiva desde múltiples fuentes:
- Identificar fuentes de datos: Identifique las diversas fuentes desde las cuales se deben integrar los datos. Esto puede incluir bases de datos, APIs, sistemas de archivos, plataformas de transmisión, fuentes de datos externas o incluso sistemas heredados.
- Comprender formatos y estructuras de datos: Adquiera un profundo entendimiento de los formatos y estructuras de las fuentes de datos. Esto incluye saber si los datos son estructurados, semi-estructurados (por ejemplo, JSON, XML) o no estructurados (por ejemplo, texto, imágenes), y el esquema o metadatos asociados con cada fuente.
- Extracción de datos: Extraiga datos de las fuentes identificadas utilizando métodos apropiados. Esto puede implicar técnicas como consultas SQL, web scraping, llamadas a API, análisis de registros o consumo de colas de mensajes, dependiendo de la fuente específica y su accesibilidad.
- Transformación de datos: Transforme los datos extraídos en un formato o esquema común que pueda integrarse fácilmente. Esto puede implicar limpieza de datos, normalización, eliminación de duplicados o estandarización. Puede ser necesario mapear campos de datos entre diferentes fuentes para garantizar la consistencia.
- Integración de datos: Integre los datos transformados de diferentes fuentes en un modelo de datos unificado o sistema de destino. Esto se puede hacer mediante procesos ETL (extracción, transformación, carga), herramientas de integración de datos o scripts personalizados.
- Mapeo y unión de datos: Defina las relaciones y mapeos entre elementos de datos de diferentes fuentes. Esto puede implicar identificar identificadores clave o atributos comunes para unir y consolidar datos con precisión.
- Aseguramiento de la calidad de datos: Implemente controles de calidad de datos y procesos de validación para garantizar la precisión, integridad y consistencia de los datos integrados. Esto puede incluir la verificación de tipos de datos, comprobaciones de rango, unicidad e integridad referencial.
- Gobernanza y seguridad de datos: Considere prácticas de gobernanza de datos, como controles de acceso, enmascaramiento de datos y cifrado, para proteger datos sensibles durante el proceso de integración.
- Actualizaciones de datos incrementales: Establezca mecanismos para manejar actualizaciones incrementales de datos desde diversas fuentes. Esto incluye el seguimiento de cambios, la gestión de versiones de datos y el procesamiento eficiente solo de los datos actualizados o nuevos para minimizar la sobrecarga de procesamiento.
- Monitoreo y manejo de errores: Implemente mecanismos de monitoreo para seguir la salud y el rendimiento de los procesos de integración de datos. Configure alertas y mecanismos de manejo de errores para identificar y resolver problemas de manera oportuna.
- Escalabilidad y optimización de rendimiento: Diseñe el proceso de integración para manejar grandes volúmenes de datos de manera eficiente. Esto puede implicar técnicas como el procesamiento paralelo, la partición, el almacenamiento en caché o el uso de marcos de trabajo de cómputo distribuido.
- Documentación: Documente el proceso de integración de datos, incluida la información de la fuente de datos, las reglas de transformación, los mapeos de datos y cualquier consideración relevante. Esta documentación ayuda a mantener la solución de integración y facilita el intercambio de conocimientos dentro del equipo.
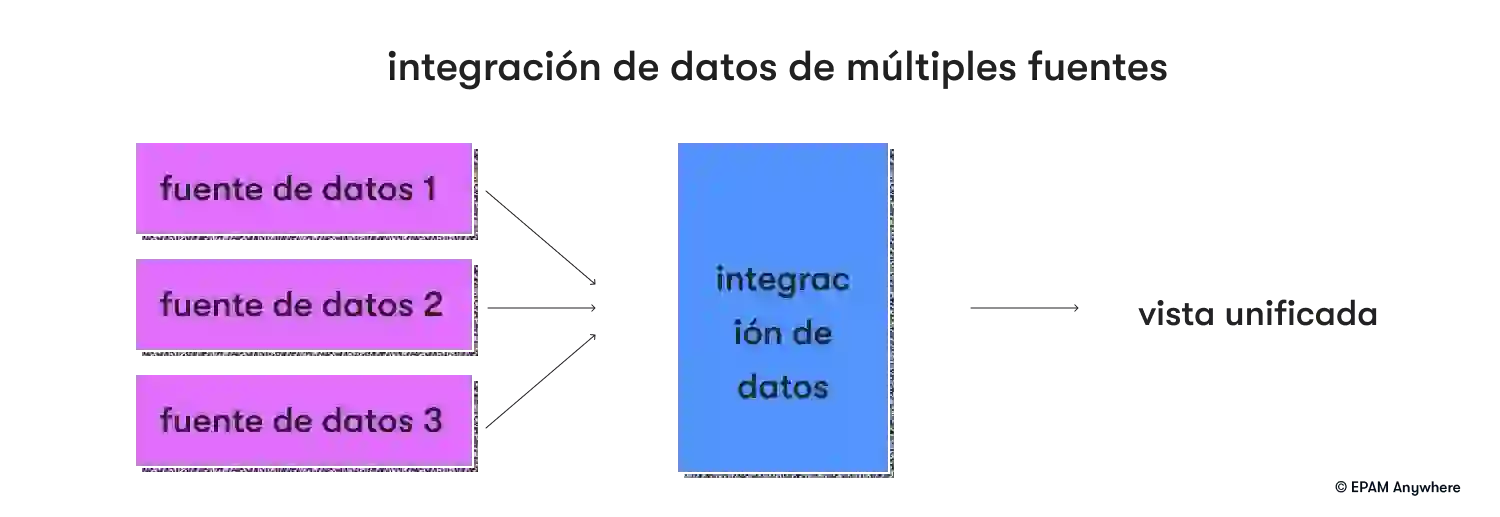
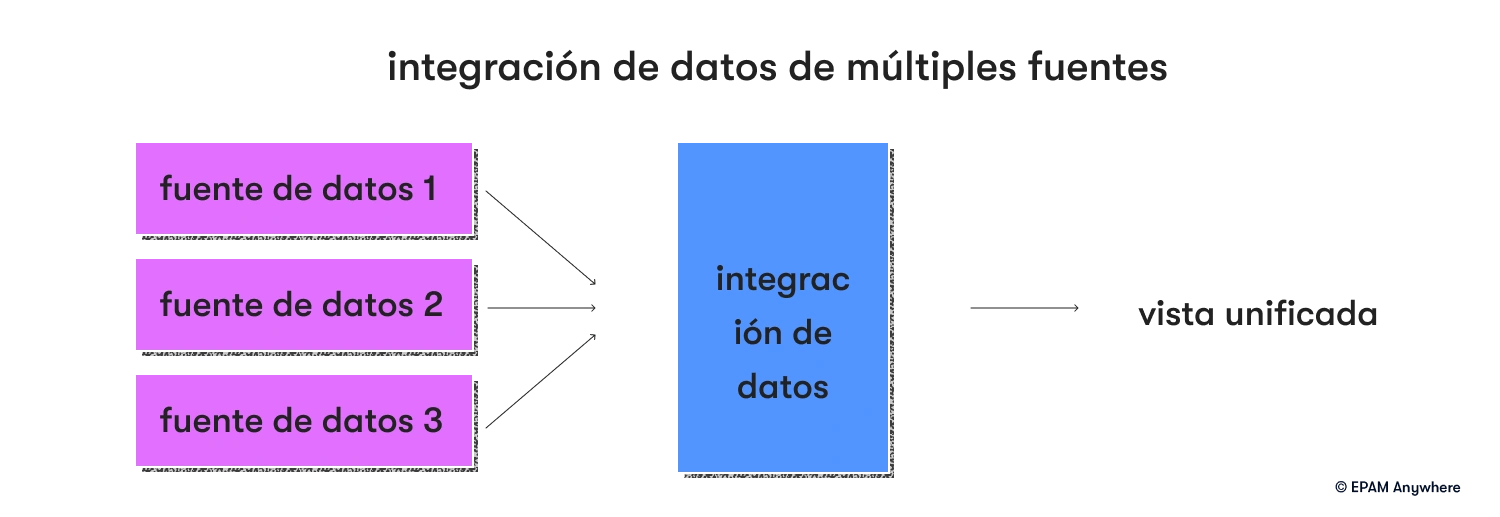
Recuerde, el enfoque específico para integrar datos de múltiples fuentes puede variar según los requisitos del proyecto, los recursos disponibles y la tecnología. Una estrategia de integración de datos bien diseñada garantiza la coherencia, precisión y disponibilidad de los datos para aplicaciones, informes y análisis posteriores.
3. ¿Qué herramientas de visualización de datos has utilizado para informes y análisis?
Aquí tienes una lista de herramientas comúnmente utilizadas para la visualización de datos en informes y análisis:
- Tableau: Tableau es una herramienta ampliamente utilizada para la visualización de datos que permite a los usuarios crear paneles interactivos, informes y visualizaciones. Ofrece una interfaz amigable y es compatible con una variedad de fuentes de datos.
- Power BI: Power BI, desarrollado por Microsoft, es otra herramienta popular para la visualización de datos y la inteligencia empresarial. Ofrece una variedad de opciones de visualización, conectores de datos, prácticas de automatización e integración con otros productos de Microsoft.
- QlikView: QlikView proporciona capacidades interactivas y dinámicas de visualización de datos. Permite a los usuarios crear modelos de datos asociativos, realizar análisis ad hoc y construir paneles visualmente atractivos.
- Looker: Looker es una plataforma que combina la exploración de datos, la visualización y la analítica integrada. Permite a los usuarios construir paneles personalizados y explorar datos en un entorno colaborativo.
- D3.js: D3.js (Data-Driven Documents) es una biblioteca de JavaScript para crear visualizaciones personalizadas y altamente interactivas. Proporciona un conjunto poderoso de herramientas para la manipulación de datos y la representación de elementos visuales basados en datos.
- Google Data Studio: Google Data Studio es una herramienta gratuita para crear paneles interactivos e informes. Se integra con varios servicios de Google y permite compartir y colaborar fácilmente.
- Plotly: Plotly es una biblioteca de visualización de datos flexible y de código abierto disponible para varios lenguajes de programación. Ofrece una amplia gama de tipos de gráficos y permite la personalización de visualizaciones.
- Grafana: Grafana es una herramienta de código abierto popular utilizada para la analítica y el monitoreo en tiempo real. Admite diversas fuentes de datos y proporciona paneles y paneles personalizables.
- Apache Superset: Apache Superset es una plataforma de exploración y visualización de datos de código abierto. Ofrece un conjunto completo de visualizaciones interactivas, paneles y consultas basadas en SQL.
- Salesforce Einstein Analytics: Salesforce Einstein Analytics es una plataforma de análisis en la nube que permite a los usuarios crear visualizaciones, explorar datos y obtener información dentro del ecosistema de Salesforce.
- MATLAB: MATLAB es un entorno de programación y análisis que incluye capacidades de visualización de datos poderosas para aplicaciones científicas e ingenieriles.

4. ¿Cómo utilizas los datos para tomar decisiones empresariales mejoradas?
La toma de decisiones basada en datos implica aprovechar los datos, analizarlos en busca de información y incorporar esa información en el proceso de toma de decisiones. Siguiendo estos pasos, puedes mejorar la toma de decisiones, hacer un seguimiento del progreso y lograr mejores resultados:
- Recopila los datos adecuados: Comienza recopilando los datos adecuados que sean aplicables a las decisiones que estás tratando de tomar. Asegúrate de recopilar la mayor cantidad de datos cuantitativos posible en función de las preguntas que tengas.
- Desarrolla un marco analítico: Crea un marco analítico para evaluar los datos y establecer indicadores clave de rendimiento (KPI) para evaluar los datos en el proceso de toma de decisiones. Asegúrate de definir claramente el éxito para el análisis.
- Analiza e interpreta los datos: Utiliza el marco analítico para analizar e interpretar los datos y obtener información significativa para la toma de decisiones.
- Aplica los datos: Aplica los datos para informar los procesos de toma de decisiones e identificar áreas de mejora.
- Supervisa y realiza un seguimiento del rendimiento: Supervisa y realiza un seguimiento del rendimiento para asegurarte de que estás tomando decisiones basadas en los mejores conocimientos impulsados por datos disponibles.
5. Explica la diferencia entre el procesamiento por lotes y el streaming en tiempo real. ¿Cuándo elegirías uno sobre el otro en un proyecto de ingeniería de datos?
El procesamiento por lotes implica recopilar grandes cantidades de datos durante un período de tiempo y luego enviarlos a un sistema para procesarlos en grandes bloques. Este método se utiliza típicamente para analizar y procesar datos más estáticos e históricos.
El streaming en tiempo real implica recopilar y analizar continuamente datos en pequeños fragmentos a medida que llegan en tiempo real. Este método se utiliza típicamente para explorar conjuntos de datos que son dinámicos y actualizados.
La elección entre uno u otro en un proyecto de ingeniería de datos depende de la naturaleza de los datos y los resultados que buscas. El streaming en tiempo real puede ser la mejor opción si necesitas un análisis actualizado para pronosticar o predecir resultados. Sin embargo, si necesitas construir un modelo basado en datos recopilados a lo largo del tiempo y en sus tendencias a largo plazo, entonces el procesamiento por lotes puede ser más útil.
prueba una entrevista técnica con nosotros
Envíanos tu currículum y recibe una invitación a una entrevista técnica para uno de nuestros trabajos disponibles que coincida con tu perfil.
6. Describe tu experiencia trabajando con plataformas de almacenamiento y procesamiento de datos basadas en la nube (por ejemplo, AWS, GCP, Azure). ¿Qué servicios has utilizado y qué beneficios proporcionaron?
Platforms such as AWS (Amazon Web Services), GCP (Google Cloud Platform), and Azure (Microsoft Azure) provide a range of services for data storage, processing, and analytics. Here are some commonly utilized services within these platforms and their benefits:
- Amazon S3 (Simple Storage Service): S3 es un servicio de almacenamiento de objetos que proporciona almacenamiento escalable, duradero y seguro para diversos tipos de datos. Ofrece alta disponibilidad, cifrado de datos y una fácil integración con otros servicios de AWS, lo que lo convierte en una opción confiable para almacenar grandes volúmenes de datos.
- Google Cloud Storage: Similar a Amazon S3, Google Cloud Storage proporciona almacenamiento de objetos seguro y escalable con características como cifrado de datos, versionado y accesibilidad global. Se integra bien con otros servicios de GCP y ofrece opciones de almacenamiento multi-regional, regional y nearline.
- Azure Blob Storage: Azure Blob Storage es una solución escalable y rentable de almacenamiento de objetos. Ofrece opciones de almacenamiento en niveles, incluyendo niveles de acceso en caliente, frío y archivo, lo que permite a los usuarios optimizar los costos según la frecuencia de acceso a los datos. Blob Storage también proporciona cifrado, versionado e integración sin problemas con otros servicios de Azure.
- AWS Glue: Glue es un servicio ETL que simplifica el proceso de preparación y transformación de datos para análisis. Ofrece catalogación automática de datos, limpieza de datos y capacidades de transformación de datos automatizadas, lo que reduce el tiempo y el esfuerzo requeridos para la preparación de datos.
- Google BigQuery: BigQuery es un almacén de datos y plataforma de análisis sin servidor. Permite a los usuarios analizar conjuntos de datos grandes de manera rápida con su infraestructura escalable y admite consultas SQL y capacidades de aprendizaje automático. El modelo de precios de pago por consulta de BigQuery y su integración sin problemas con otros servicios de GCP lo convierten en una poderosa solución de análisis.
- Azure Data Lake Analytics: Azure Data Lake Analytics es un servicio de análisis distribuido que puede procesar cantidades masivas de datos mediante un lenguaje declarativo similar a SQL o U-SQL. Aprovecha el poder de Azure Data Lake Storage y proporciona escalabilidad bajo demanda para cargas de trabajo de análisis de big data.
- AWS EMR (Elastic MapReduce): EMR es una plataforma de clúster gestionada que simplifica el procesamiento de datos a gran escala utilizando marcos populares como Apache Hadoop, Spark y Hive. Permite una fácil gestión de clústeres, escalabilidad automática e integración con otros servicios de AWS.
Los beneficios de utilizar estas plataformas incluyen escalabilidad, rentabilidad, flexibilidad, confiabilidad y la capacidad de aprovechar una amplia gama de servicios e integraciones. Proporcionan una infraestructura robusta para almacenar y procesar datos, lo que permite a las organizaciones centrarse en la analítica de datos, la generación de información y la innovación sin la carga de gestionar una infraestructura compleja.

7. ¿Cómo manejas las preocupaciones de seguridad y privacidad de los datos en un proyecto de ingeniería de datos?
Manejar las preocupaciones de seguridad y privacidad de los datos es crucial en cualquier proyecto de ingeniería de datos para proteger información sensible y garantizar el cumplimiento de las regulaciones relevantes. Para hacerlo, se deben implementar las siguientes prácticas:
- Crea una política de seguridad y privacidad de datos y evalúa el nivel de cumplimiento por parte de todos los participantes del proyecto de ingeniería de datos.
- Almacena datos en entornos seguros y privados, incluyendo configuraciones de red y firewall adecuadas, autenticación de usuarios finales y control de acceso.
- Utiliza cifrado al transferir y almacenar datos sensibles.
- Autentica y autoriza el acceso a datos restringidos.
- Utiliza acuerdos de no divulgación (NDA) para proteger la información confidencial de la empresa.
- Asegúrate de que todas las partes contribuyentes cumplan con las leyes y regulaciones de privacidad de datos aplicables.
- Monitorea regularmente sistemas y redes en busca de actividad sospechosa.
- Educa a los trabajadores sobre las mejores prácticas de seguridad.
- Realiza auditorías periódicas de seguridad y privacidad.
- Realiza copias de seguridad regulares de datos y prueba modelos.
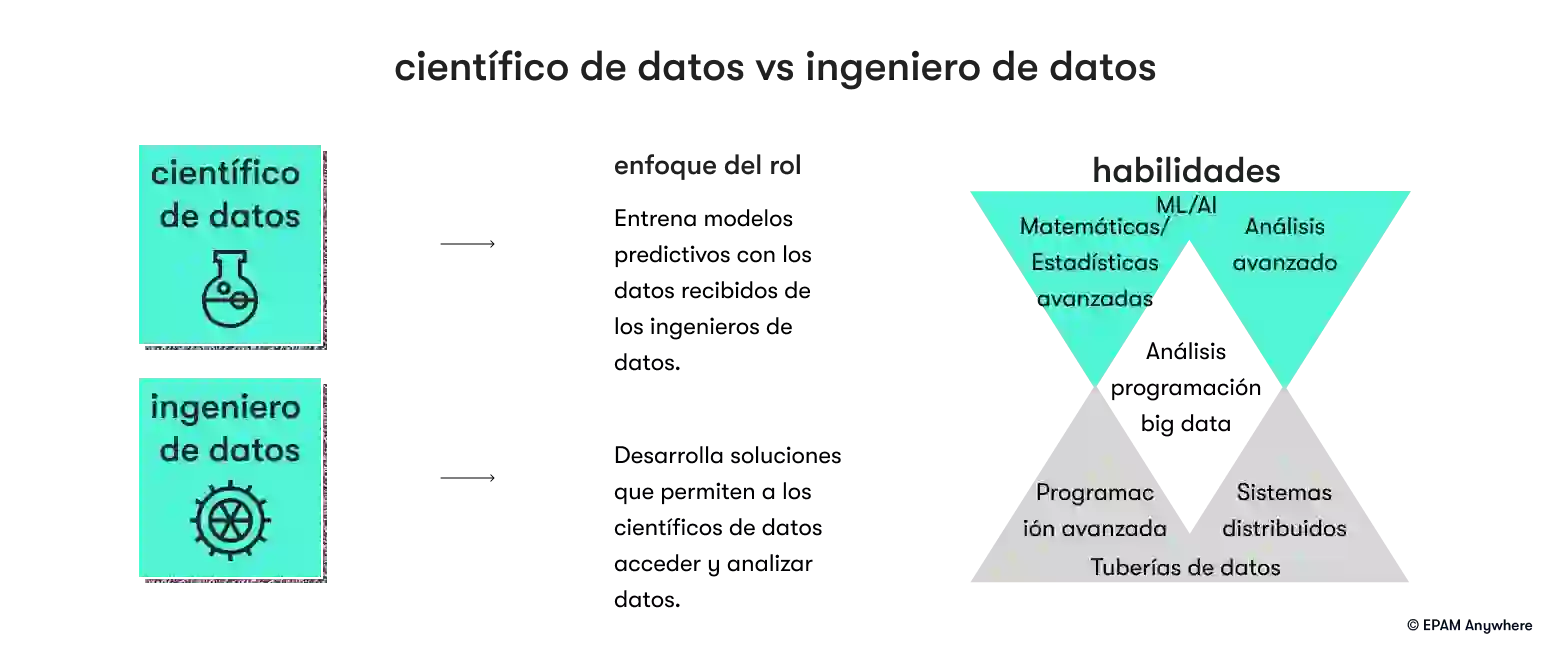
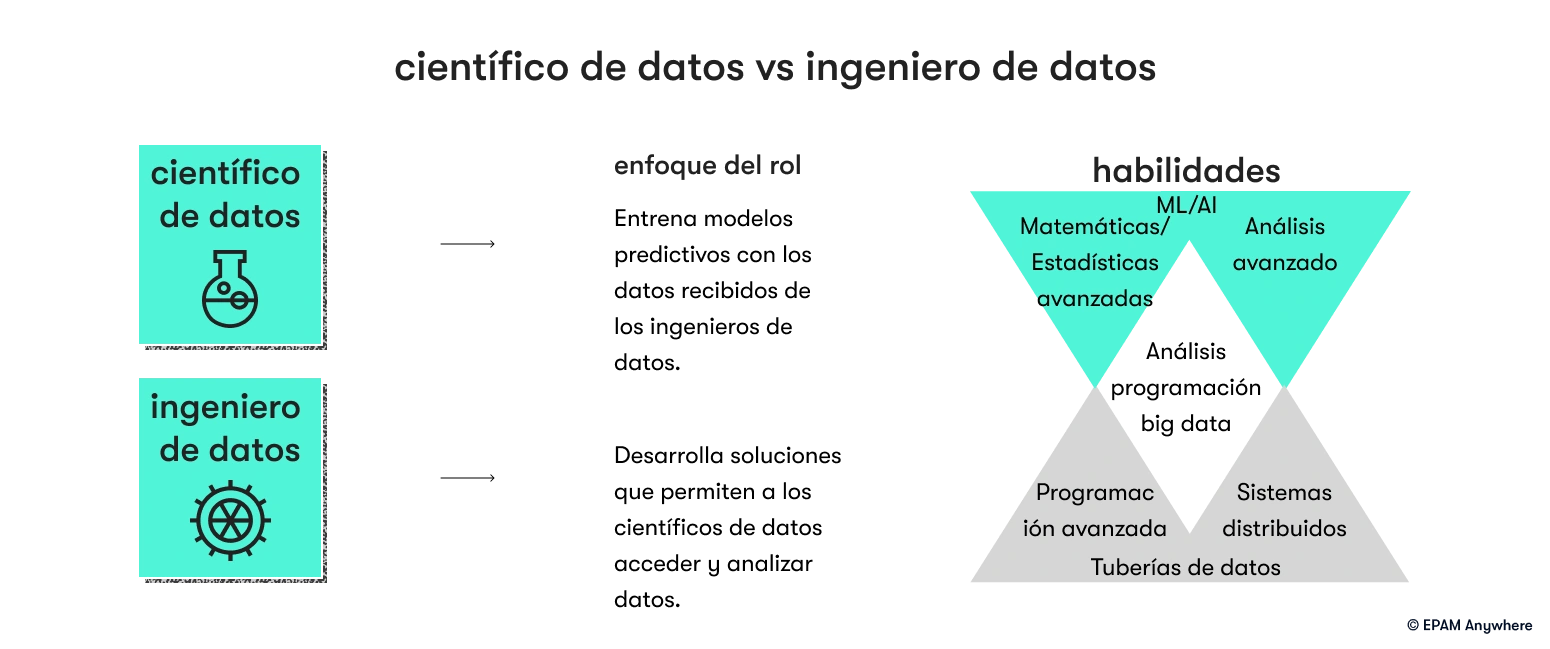
8. ¿Cuál es la diferencia entre un ingeniero de datos y un científico de datos?
Un ingeniero de datos se enfoca en diseñar y mantener la infraestructura y los sistemas de datos para el procesamiento, almacenamiento e integración eficientes de datos. Maneja tuberías de datos, bases de datos y almacenes de datos.
Un científico de datos se enfoca en analizar datos, extraer conocimientos y construir modelos para análisis predictivos y toma de decisiones. Aplica técnicas estadísticas, desarrolla modelos de aprendizaje automático y comunica hallazgos a las partes interesadas.
9. ¿Puedes explicar el concepto de particionamiento de datos y cómo ayuda a la eficiencia del procesamiento de datos?
El particionamiento de datos es una técnica utilizada en el procesamiento de datos para dividir un conjunto de datos grande en segmentos más pequeños y manejables llamados particiones. Cada partición contiene un subconjunto de los datos que está lógicamente relacionado o tiene un atributo en común.
Al particionar los datos, se vuelve más fácil procesar y analizar grandes volúmenes de datos de manera eficiente. Así es cómo el particionamiento de datos ayuda a la eficiencia del procesamiento de datos:
- Mejora del rendimiento de consultas: El particionamiento permite el procesamiento en paralelo de datos en múltiples nodos o unidades de procesamiento. Las consultas y cálculos pueden ejecutarse simultáneamente en diferentes particiones, lo que conduce a tiempos de respuesta más rápidos y un rendimiento general mejorado.
- Reducción de la exploración de datos: Con el particionamiento de datos, el sistema puede realizar exploraciones selectivas accediendo solo a las particiones relevantes en lugar de escanear el conjunto de datos completo. Esto reduce la cantidad de datos que deben procesarse, lo que resulta en una ejecución de consultas más rápida.
- Mejora de la filtración de datos: El particionamiento permite una filtración de datos eficiente basada en criterios o condiciones específicas. Dado que los datos se organizan en particiones según atributos, las operaciones de filtrado pueden realizarse directamente en las particiones relevantes, lo que reduce la necesidad de escanear datos innecesarios.
- Carga y descarga de datos eficiente: El particionamiento facilita procesos más rápidos de carga y descarga de datos. En lugar de cargar o descargar el conjunto de datos completo, las operaciones pueden realizarse partición por partición, lo que mejora las velocidades de transferencia de datos y reduce el tiempo necesario para la ingestión o extracción de datos.
- Mejor mantenimiento de datos: El particionamiento puede simplificar tareas de mantenimiento de datos. Por ejemplo, operaciones a nivel de partición, como archivado, copias de seguridad o gestión del ciclo de vida de datos, pueden realizarse selectivamente en particiones específicas, lo que permite un control más granular y una gestión eficiente de datos.
- Optimización de la utilización de recursos: El particionamiento permite la distribución de carga de trabajo en múltiples recursos o nodos de procesamiento. Al distribuir las particiones de datos entre los recursos disponibles, el sistema puede aprovechar la paralelización y optimizar la utilización de recursos, lo que resulta en un procesamiento de datos más rápido y una mejor escalabilidad.
- Mejora de la disponibilidad y recuperación de datos: El particionamiento puede mejorar la disponibilidad y las capacidades de recuperación de datos. En caso de fallos o corrupción de datos, se puede realizar una recuperación o restauración a nivel de partición, lo que reduce el impacto y el tiempo necesario para la restauración de datos.
La efectividad del particionamiento de datos depende de factores como la distribución de datos, los patrones de consulta y el marco o base de datos específicos utilizados para el procesamiento de datos. Estrategias de particionamiento adecuadas, como la elección de las claves o criterios de particionamiento adecuados, son esenciales para lograr una eficiencia óptima en el procesamiento de datos y el rendimiento de las consultas.
10. Explica el concepto de linaje de datos y su importancia en un contexto de ingeniería de datos.
El linaje de datos es el proceso de trazabilidad y responsabilidad de todas las actividades que ocurren en los datos de una organización. El linaje de datos rastrea cada elemento de datos individual a través de cada etapa y componente del flujo de procesamiento de datos, desde su origen, como una base de datos, hasta su consumo, como un panel de análisis de autoservicio. Esto implica comprender cómo cada paso en el proceso contribuye al producto final.
El linaje de datos es importante en un contexto de ingeniería de datos ya que proporciona visibilidad sobre el flujo de datos y mejora la trazabilidad, auditoría y procesos de cumplimiento. El linaje de datos ayuda a identificar conjuntos de datos que están conectados y dependen entre sí, y puntos de datos necesarios para decisiones comerciales. Esto ayuda a prevenir errores en el proceso de ingeniería de datos y permite una depuración más fácil y rápida. También aumenta la confianza en los datos utilizados, y cualquier cambio en el flujo de datos se puede identificar y corregir rápidamente.


Preguntas y respuestas de entrevistas de comportamiento para ingenieros de datos
A medida que aumenta la demanda de ingenieros de datos calificados, se vuelve crucial que los candidatos sobresalgan en entrevistas de comportamiento que evalúen su conocimiento técnico, habilidades para resolver problemas y habilidades interpersonales. Exploremos una colección de preguntas comunes de entrevistas de comportamiento para ingenieros de datos, junto con respuestas de ejemplo que pueden ayudar a los candidatos aspirantes a prepararse de manera efectiva y mostrar su experiencia en el campo.
11. Describe una situación en la que tuviste que colaborar con equipos interfuncionales para entregar un proyecto de ingeniería de datos. ¿Cómo aseguraste una comunicación y colaboración efectivas?
Una respuesta de ejemplo:
“En un proyecto reciente de ingeniería de datos, colaboré tanto con los equipos de ciencia de datos como con los de ingeniería de software. Para garantizar una comunicación y colaboración efectivas, inicié reuniones regulares para alinear nuestros objetivos y aclarar los requisitos del proyecto. Me aseguré de escuchar activamente las perspectivas y preocupaciones de todos y fomenté el diálogo abierto. Además, creé una plataforma de gestión de proyectos compartida donde podíamos hacer un seguimiento del progreso, asignar tareas y discutir desafíos o dependencias. Manteniendo canales de comunicación claros y transparentes, fomentando un entorno de colaboración y enfatizando la importancia del trabajo en equipo interfuncional, pudimos entregar con éxito el proyecto a tiempo y superar las expectativas.”
12. Describe una ocasión en la que tuviste que solucionar y resolver un problema crítico en una tubería de datos bajo presión de tiempo. ¿Cómo manejaste la situación?
Una respuesta de ejemplo:
“En un trabajo anterior, nos encontramos con una falla repentina en una tubería de datos crítica que resultó en un importante acumulación de datos. Con el tiempo siendo esencial, inicié de inmediato un análisis de la causa raíz para identificar el problema. Trabajé en estrecha colaboración con el equipo de operaciones para investigar los registros del sistema, monitoreé el tráfico de red y examiné las conexiones de la base de datos. A través de un análisis exhaustivo, descubrimos que la falla fue causada por un interruptor de red defectuoso. Para resolver rápidamente el problema, coordiné con el equipo de redes para reemplazar el interruptor defectuoso y redirigir el tráfico a una ruta de respaldo. Simultáneamente, implementé medidas temporales para priorizar y procesar la acumulación de datos. Al demostrar habilidades sólidas para resolver problemas, coordinar eficazmente con diferentes equipos e implementar acciones correctivas rápidas, resolvimos con éxito el problema y minimizamos las interrupciones en el procesamiento de datos.”
Solicita trabajos remotos de ingeniero de datos en EPAM Anywhere
Si eres un ingeniero de datos en busca de oportunidades remotas, no busques más allá de EPAM Anywhere. EPAM Anywhere ofrece emocionantes posiciones remotas para talentosos ingenieros de datos, lo que te permite trabajar desde tu ubicación y construir una carrera orientada al trabajo remoto en tecnología. Con nuestra presencia global, tendrás la oportunidad de colaborar con profesionales de renombre en proyectos destacados mientras disfrutas de la flexibilidad del trabajo remoto.

El Equipo Editorial de EPAM Anywhere es un colectivo internacional de ingenieros de software senior, directivos y profesionales de la comunicación que crean, revisan y comparten sus puntos de vista sobre tecnología, carrera, trabajo remoto y el dia a día aquí en Anywhere.
El Equipo Editorial de EPAM Anywhere es un colectivo internacional de ingenieros de software senior, directivos y profesionales de la comunicación que crean, revisan y comparten sus puntos de vista sobre tecnología, carrera, trabajo remoto y el dia a día aquí en Anywhere.
Explora nuestra Política Editorial para conocer más sobre nuestros estándares de creación de contenido.
leer más













