




Las siguientes preguntas y respuestas han sido revisadas y verificadas por Abhijeet Singh, Ingeniero de Software Senior de SQL (Oracle PL/SQL) en EPAM Anywhere. ¡Muchas gracias, Abhijeet!
¿Estás preparándote para tu próxima entrevista técnica? Aquí obtendrás un conjunto de preguntas de entrevista seleccionadas para desarrolladores SQL, con una explicación detallada y respuestas bien pensadas, brindando una comprensión integral de los conceptos.
Sumergirte en esta colección de preguntas y respuestas de entrevistas SQL mejorará tus habilidades para resolver problemas, te dará valiosos conocimientos sobre desafíos reales de SQL y mejorará tu experiencia técnica.
Así que, ¡vamos a sumergirnos y embarcarnos en un viaje transformador a través del mundo de SQL, empoderándote para sobresalir en tu próxima entrevista y alcanzar nuevas alturas en tu carrera!
¿buscas un trabajo remoto?
No busques más. Envía tu CV y encontraremos el mejor trabajo remoto de automatización de QA en EPAM Anywhere que se adapte a tus habilidades.
Preguntas de entrevista para desarrolladores de SQL para estudiantes de primer año
Hemos compilado un conjunto de preguntas de entrevista para desarrolladores SQL adaptadas a recién graduados. Estas preguntas te ayudarán a evaluar tus conocimientos sobre conceptos básicos de SQL, escritura de consultas y manipulación de bases de datos. Al familiarizarte con estas preguntas y sus respuestas, ganarás confianza para enfrentar entrevistas de SQL y mostrar tus habilidades como un prometedor desarrollador SQL. ¡Comencemos!
1. ¿Qué es SQL y cuáles son sus componentes clave?
SQL (Structured Query Language) es un lenguaje de programación estandarizado para gestionar y manipular bases de datos relacionales. Sirve como medio de comunicación entre los usuarios y las bases de datos, permitiéndoles realizar diversas tareas, como consultar datos, insertar o actualizar registros, crear y modificar estructuras de bases de datos, y controlar el acceso a los datos.
Los componentes clave de SQL incluyen:
- Lenguaje de definición de datos (DDL): Las declaraciones DDL se utilizan para definir y modificar la estructura de la base de datos. Incluyen comandos como CREATE, ALTER y DROP, que se utilizan para crear o modificar tablas, índices, vistas, restricciones y otros objetos de la base de datos.
- Lenguaje de manipulación de datos (DML): Las declaraciones DML se utilizan para recuperar, insertar, actualizar y eliminar datos en una base de datos. Los principales comandos DML son SELECT, INSERT, UPDATE y DELETE, que permiten a los usuarios realizar acciones sobre los datos almacenados en las tablas.
- Lenguaje de control de datos (DCL): Las declaraciones DCL se utilizan para gestionar los privilegios de los usuarios y controlar el acceso a la base de datos. GRANT y REVOKE son los principales comandos DCL, que permiten otorgar o revocar permisos a usuarios o roles.
- Lenguaje de control de transacciones (TCL): Las declaraciones TCL se utilizan para gestionar las transacciones dentro de una base de datos. Incluyen comandos como COMMIT, ROLLBACK y SAVEPOINT, que garantizan la consistencia e integridad de los datos al definir los límites de las transacciones y controlar sus resultados.

2. Diferenciar entre las sentencias SELECT e INSERT de SQL
Las declaraciones SELECT e INSERT en SQL tienen propósitos distintos y funcionalidades diferentes. Aquí tienes una descripción de las diferencias entre ambas:
Declaración SELECT
La declaración SELECT recupera datos de una o más tablas en una base de datos. Su propósito principal es consultar y obtener información específica basada en condiciones especificadas. La declaración SELECT te permite especificar las columnas que deseas recuperar, aplicar filtros usando la cláusula WHERE, unir múltiples tablas, realizar cálculos y ordenar el conjunto de resultados. No modifica los datos en las tablas; solo los recupera y los presenta en el formato deseado.
Ejemplo: Supongamos que deseas recuperar los nombres y departamentos de todos los empleados cuyos apellidos comienzan con "Smith". La declaración SELECT se puede utilizar de la siguiente manera:
Declaración INSERT
La declaración INSERT se utiliza para insertar nuevos datos en una tabla. Permite agregar una o más filas de datos a una tabla especificada. La declaración INSERT requiere que especifiques el nombre de la tabla y proporciones los valores o expresiones para cada columna correspondiente a los datos que deseas insertar. Agrega nuevos registros a la tabla, aumentando su tamaño y modificando los datos almacenados.
Ejemplo: Supongamos que deseas agregar un nuevo empleado a la tabla "Empleados". Tienes los detalles del empleado, incluyendo su ID, nombre, apellido y departamento. Puedes usar la declaración INSERT de la siguiente manera:
En resumen, mientras que la declaración SELECT recupera y presenta datos de la base de datos sin modificarlos, la declaración INSERT agrega nuevos datos a una tabla, modificando así la base de datos al agregar nuevos registros.
3. ¿Qué son las claves primarias y las claves foráneas en SQL?
En SQL, las claves primarias y las claves foráneas se utilizan para establecer relaciones entre tablas en una base de datos relacional. A continuación, se explica cada una de ellas:
Una clave primaria es una columna o un conjunto de columnas en una tabla que identifica de manera única cada fila en esa tabla. Proporciona una forma de garantizar la integridad de los datos y aplicar reglas de integridad de entidad. La clave primaria debe tener las siguientes características:
- Debe contener valores únicos.
- No puede tener valores NULL.
- Solo puede haber una clave primaria definida por tabla.
Típicamente, la clave primaria se crea cuando se diseña la tabla inicialmente y se utiliza para identificar de manera única cada registro en la tabla. Las claves primarias se utilizan a menudo como base para establecer relaciones con otras tablas mediante claves foráneas.
Una clave foránea es una columna o un conjunto de columnas en una tabla que hace referencia a la clave primaria de otra tabla. Establece un vínculo entre dos tablas, aplicando la integridad referencial y definiendo una relación entre ellas. La columna de clave foránea en una tabla hace referencia a la columna de clave primaria en otra tabla.
La clave foránea asegura que los valores en la columna de referencia (columna de clave foránea) coincidan con los valores en la columna de referencia (columna de clave primaria). Proporciona una forma de mantener la consistencia e integridad de los datos entre tablas relacionadas.

4. ¿Cuál es el propósito de la cláusula WHERE en las consultas SQL?
La cláusula WHERE en las consultas SQL se utiliza para filtrar filas de una tabla basándose en condiciones especificadas. Permite recuperar solo las filas que cumplen con criterios específicos, reduciendo así el conjunto de resultados. El propósito principal de la cláusula WHERE es extraer selectivamente datos que coinciden con ciertas condiciones, lo que hace que los resultados de la consulta sean más significativos y relevantes.
Así es cómo funciona la cláusula WHERE en las consultas SQL:
- Filtrado de filas: La cláusula WHERE se coloca después de la cláusula FROM en una declaración SELECT. Contiene una o más condiciones que evalúan a verdadero o falso. Las filas que cumplen estas condiciones se incluyen en el conjunto de resultados, mientras que las filas que no cumplen las condiciones se excluyen.
- Expresiones condicionales: Las condiciones en la cláusula WHERE suelen implicar comparaciones, operadores lógicos (como AND, OR y NOT) y funciones SQL. Estas condiciones pueden basarse en valores en columnas específicas, constantes o una combinación de ambos.
Ejemplo: Supongamos que tenemos una tabla llamada "Empleados" con columnas como "IDEmpleado," "Nombre," "Apellido" y "Departamento". Si deseas recuperar los detalles de los empleados que trabajan en el departamento "Ventas", puedes utilizar la cláusula WHERE de la siguiente manera:
En este ejemplo, la cláusula WHERE filtra las filas donde la columna "Departamento" no es igual a 'Ventas'. Solo las filas que satisfacen esta condición se incluirán en el conjunto de resultados.
La cláusula WHERE también se puede utilizar con otras declaraciones SQL como UPDATE, DELETE e INSERT para aplicar condiciones al modificar o insertar datos.
En general, la cláusula WHERE proporciona un mecanismo potente para filtrar datos y recuperar subconjuntos específicos de filas de una tabla basándose en condiciones dadas, lo que permite una recuperación de datos más precisa y dirigida.
5. Describe las diferencias entre INNER JOIN y OUTER JOIN en SQL.
En SQL, las operaciones de JOIN se utilizan para combinar filas de dos o más tablas en función de una columna relacionada entre ellas. El INNER JOIN y el OUTER JOIN son dos tipos de operaciones de JOIN con características distintas. A continuación, se presenta una explicación de sus diferencias:
INNER JOIN:
- Un INNER JOIN devuelve solo las filas donde hay una coincidencia entre las columnas de unión en ambas tablas.
- Combina filas de dos o más tablas en función de una condición especificada, llamada predicado de unión.
- Las filas resultantes incluyen solo los registros coincidentes de ambas tablas.
- Si no hay registros coincidentes, las filas de ambas tablas se excluyen del conjunto de resultados.
- La sintaxis para un INNER JOIN es la siguiente:
OUTER JOIN:
- Un OUTER JOIN devuelve todas las filas de una tabla y las filas coincidentes de la(s) otra(s) tabla(s). También incluye filas no coincidentes.
- Combina filas de dos o más tablas en función de una condición especificada, al igual que un INNER JOIN.
- Sin embargo, un OUTER JOIN incluye filas no coincidentes al llenar los valores faltantes con NULL.
Existen tres tipos de OUTER JOIN: LEFT OUTER JOIN, RIGHT OUTER JOIN y FULL OUTER JOIN.
- LEFT OUTER JOIN: Devuelve todas las filas de la tabla izquierda y las filas coincidentes de la(s) tabla(s) derecha(s). Si no hay coincidencias, se llenan los valores NULL en las columnas de la tabla derecha.
- RIGHT OUTER JOIN: Devuelve todas las filas de la tabla derecha y las filas coincidentes de la(s) tabla(s) izquierda(s). Si no hay coincidencias, se llenan los valores NULL en las columnas de la tabla izquierda.
- FULL OUTER JOIN: Devuelve todas las filas de ambas tablas, incluidas las filas coincidentes y no coincidentes. Si no hay coincidencias, se llenan los valores NULL en las columnas de la tabla no coincidente.
- La sintaxis para un OUTER JOIN varía según el tipo específico de OUTER JOIN, pero aquí tienes un ejemplo de LEFT OUTER JOIN:
Preguntas de la entrevista del desarrollador de SQL Server para 5 años de experiencia
Con 5 años de experiencia como desarrollador de SQL Server, has alcanzado un hito significativo. A medida que te preparas para las entrevistas de trabajo como desarrollador de SQL Server en esta etapa, deberás demostrar tu experiencia en temas avanzados como administración de bases de datos, optimización de rendimiento y escritura de consultas avanzadas. En esta sección, encontrarás preguntas de entrevista seleccionadas para desarrolladores de SQL Server adaptadas a profesionales con 5 años de experiencia.

6. Explica las diferencias entre los índices agrupados (clustered) y los índices no agrupados (non-clustered) en SQL Server.
En SQL Server, los índices juegan un papel crucial en la optimización del rendimiento de la base de datos al facilitar la recuperación rápida de datos. Los dos tipos principales de índices en SQL Server son los índices agrupados (clustered indexes) y los índices no agrupados (non-clustered indexes), y difieren en su estructura y funcionalidad. Aquí están las diferencias clave:
Índice Agrupado:
- Estructura: Un índice agrupado determina el orden físico de las filas de datos en una tabla. En otras palabras, define el orden de almacenamiento físico de la tabla según la(s) columna(s) indexada(s).
- Único: Una tabla solo puede tener un índice agrupado, ya que dicta la organización física de la tabla.
- Almacenamiento de datos: Las filas de datos en una tabla con un índice agrupado se almacenan físicamente en el orden definido por la clave del índice agrupado.
- Impacto en el rendimiento: Un índice agrupado bien diseñado puede mejorar el rendimiento de las consultas para búsquedas basadas en rangos o al recuperar grandes porciones de datos. Sin embargo, puede ralentizar las operaciones de modificación de datos (como INSERT, UPDATE y DELETE) ya que el orden físico debe ajustarse.
Índice No Agrupado:
- Estructura: Un índice no agrupado crea una estructura separada que incluye la(s) columna(s) indexada(s) y un puntero a las filas de datos reales.
- Múltiples índices: Una tabla puede tener varios índices no agrupados, lo que permite diferentes estrategias de indexación según los requisitos de las consultas.
- Almacenamiento de datos: Las filas de datos en una tabla con un índice no agrupado se almacenan por separado de la estructura del índice. La estructura del índice contiene una copia de la(s) columna(s) indexada(s) y un puntero a la fila de datos correspondiente.
- Impacto en el rendimiento: Los índices no agrupados son beneficiosos para mejorar el rendimiento de las consultas al permitir una búsqueda rápida de datos según la(s) columna(s) indexada(s). Generalmente tienen un impacto mínimo en las operaciones de modificación de datos.

7. ¿Qué tipos de replicación están disponibles en SQL Server y cuándo usarías cada uno?
En SQL Server, hay tres tipos principales de replicación disponibles: replicación de instantáneas (snapshot replication), replicación transaccional (transactional replication) y replicación de mezcla (merge replication). Cada tipo sirve para propósitos específicos y se utiliza en diferentes escenarios. Aquí tienes un resumen de cada tipo de replicación y sus casos de uso típicos:
Replicación de instantáneas (Snapshot Replication):
En este tipo, se toma una instantánea de la base de datos replicada y se copia en los suscriptores. Los cambios posteriores realizados en la base de datos del publicador no se propagan automáticamente a los suscriptores. En su lugar, es necesario generar y aplicar una nueva instantánea para sincronizar los datos.
Casos de uso:
- Datos que cambian con poca frecuencia: La replicación de instantáneas es adecuada cuando los datos cambian con poca frecuencia y no se requiere una sincronización casi en tiempo real.
- Informes o distribución de datos: Puede utilizarse para distribuir datos estáticos o crear copias de solo lectura de una base de datos con fines de informes.
Replicación transaccional (Transactional Replication):
La replicación transaccional captura y replica modificaciones individuales de datos, como inserciones, actualizaciones y eliminaciones, a medida que ocurren en la base de datos del publicador. Luego, las transacciones se aplican a los suscriptores en el mismo orden en que ocurrieron.
Casos de uso:
- Sincronización de datos en tiempo real: La replicación transaccional es ideal cuando se necesita una sincronización de datos casi en tiempo real entre el publicador y los suscriptores.
- Alto volumen de transacciones: Se utiliza comúnmente en escenarios con altos volúmenes de transacciones, como sistemas de procesamiento de transacciones en línea (OLTP).
Replicación de mezcla (Merge Replication):
La replicación de mezcla es un método de replicación bidireccional que permite realizar cambios tanto en la base de datos del publicador como en las bases de datos de los suscriptores. Realiza un seguimiento y reconcilia los cambios realizados en cada réplica y resuelve conflictos que pueden surgir cuando los mismos datos se modifican en múltiples ubicaciones.
Casos de uso:
- Escenarios móviles o sin conexión: La replicación de mezcla es adecuada para escenarios donde los clientes desconectados o con conexiones ocasionales necesitan sincronizar datos con el servidor central.
- Entornos colaborativos: Se utiliza comúnmente en entornos donde múltiples usuarios o equipos deben trabajar en el mismo conjunto de datos y requieren una sincronización bidireccional.
8. ¿Cómo optimizarías una consulta lenta en SQL Server?
Para optimizar una consulta lenta en SQL Server, sigue estos pasos:
- Analiza el plan de ejecución de la consulta en busca de posibles problemas.
- Utiliza índices adecuados para mejorar el rendimiento de la consulta.
- Recupera solo las columnas y filas necesarias para minimizar la recuperación de datos.
- Optimiza las condiciones y tipos de uniones para una recuperación eficiente de datos.
- Simplifica consultas complejas dividiéndolas en partes más pequeñas.
- Actualiza las estadísticas de tablas e índices para una optimización precisa de la consulta.
- Ajusta la configuración del servidor según el hardware y la carga de trabajo.
- Considera la reescritura o el almacenamiento en caché de la consulta para mejorar el rendimiento.
- Monitorea y optimiza el rendimiento de E/S (entrada/salida).
- Mantén SQL Server actualizado y realiza el mantenimiento regular de la base de datos.
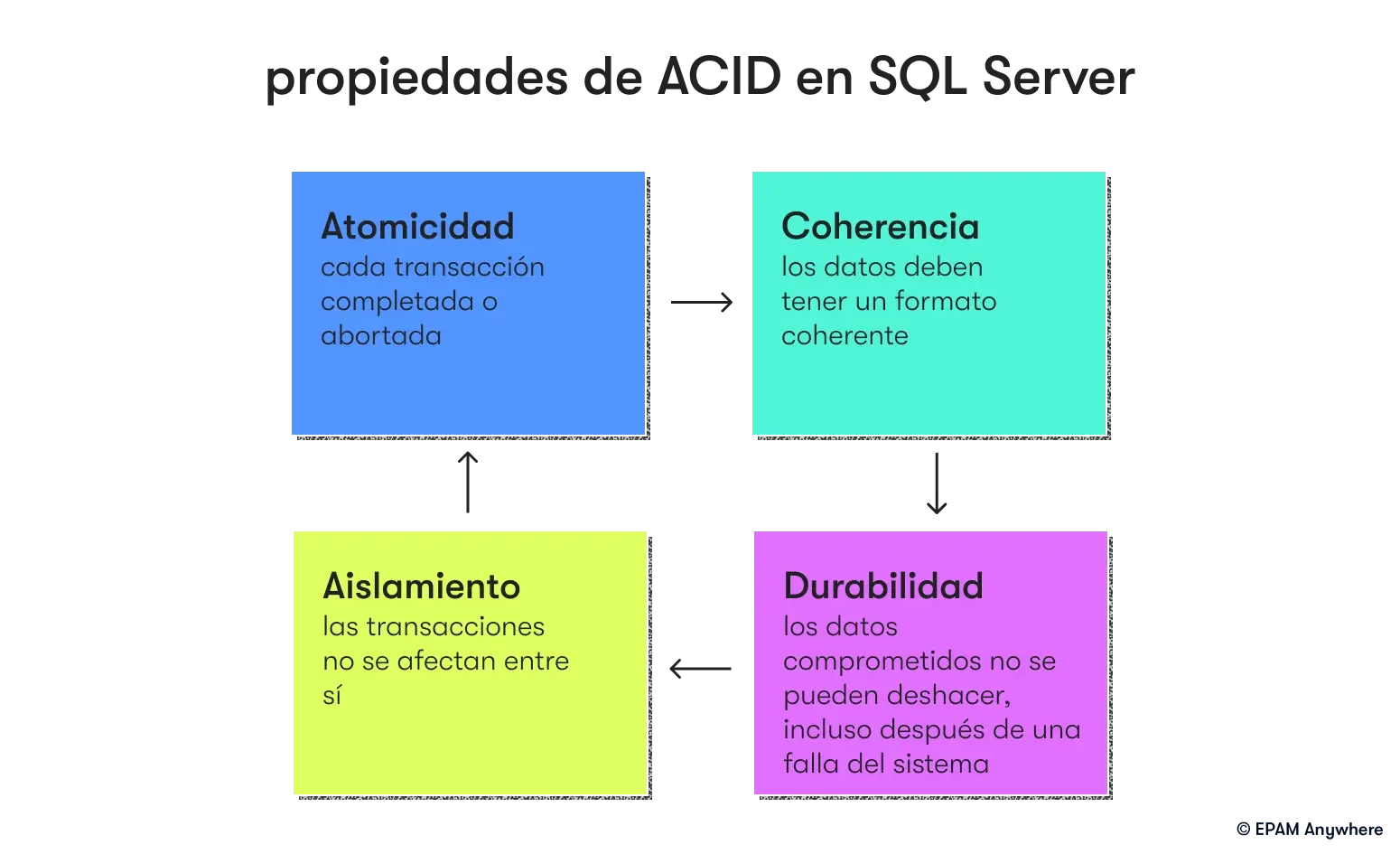
9. Describe las propiedades ACID en el contexto de las transacciones de SQL Server.
Las propiedades ACID en las transacciones de SQL Server garantizan la confiabilidad e integridad de los datos:
- Atomicidad (Atomicity): Las transacciones se tratan como una sola unidad de trabajo. Se completan y confirman todas las operaciones con éxito o ninguna de ellas, evitando datos incompletos o inconsistentes.
- Consistencia (Consistency): Las transacciones llevan la base de datos de un estado válido a otro, aplicando reglas y restricciones predefinidas. Las violaciones resultan en una reversión (rollback) para mantener la consistencia de los datos.
- Aislamiento (Isolation): Las transacciones concurrentes están aisladas entre sí para evitar interferencias y garantizar la integridad de los datos. Los niveles de aislamiento definen el equilibrio entre la concurrencia y la consistencia.
- Durabilidad (Durability): Las transacciones confirmadas se almacenan permanentemente, sobreviviendo.
Estas propiedades mantienen la confiabilidad, consistencia e integridad de las transacciones en SQL Server, lo que respalda operaciones comerciales críticas.
10. ¿Cómo manejarías los cambios en el esquema de la base de datos en un entorno de producción sin causar tiempo de inactividad?
Para manejar los cambios en el esquema de la base de datos en un entorno de producción sin tiempo de inactividad:
- Planifica y documenta cuidadosamente los cambios.
- Utiliza control de versiones para realizar un seguimiento y gestionar los cambios en el esquema.
- Prueba los cambios en un entorno que no sea de producción.
- Implementa una implementación de tipo "blue-green" para cambiar sin problemas al esquema actualizado.
- Utiliza herramientas de migración de bases de datos para una implementación controlada.
- Programa los cambios durante ventanas de mantenimiento o periodos de bajo tráfico.
- Utiliza cambios de esquema en línea o herramientas diseñadas para minimizar el tiempo de inactividad.
- Ten un plan de reversión en caso de problemas.
impulsa tu carrera con EPAM Anywhere
Solicite nuestro trabajo de desarrollador de SQL para disfrutar de un estilo de trabajo remoto para siempre y de los mejores proyectos para los clientes de Forbes Global 2000.
Preguntas de la entrevista del desarrollador de SQL para 10 años de experiencia
En esta sección, presentamos preguntas de entrevista para desarrolladores de SQL adaptadas a personas con 10 años de experiencia. Estas preguntas evalúan el conocimiento en profundidad y la experiencia del candidato en desarrollo SQL, diseño de bases de datos, optimización y conceptos avanzados de SQL.
11. Explica el concepto de optimización de consultas en SQL con ejemplos.
La optimización de consultas en SQL tiene como objetivo mejorar el rendimiento de las consultas seleccionando el plan de ejecución más eficiente. Las siguientes técnicas se utilizan comúnmente para optimizar consultas complejas:
- Analizar los planes de ejecución: Identificar cuellos de botella e ineficiencias en los planes de ejecución de las consultas.
- Estrategias de indexación: Crear o modificar índices según los requisitos de filtrado y ordenación.
- Simplificar consultas: Dividir consultas complejas en partes más pequeñas, eliminar uniones innecesarias y optimizar condiciones.
- Particionamiento: Dividir tablas grandes en particiones más pequeñas para mejorar el acceso a los datos y la paralelización.
- Caché y vistas materializadas: Utilizar mecanismos de caché y vistas precalculadas para reducir el tiempo de cálculo.
- Ajuste de consultas: Reescribir consultas subóptimas, ajustar estrategias de unión y optimizar parámetros de consulta.
- Optimización de parámetros: Ajustar los recursos del sistema y la configuración.
- Mantenimiento regular: Actualizar estadísticas, reconstruir índices y eliminar datos innecesarios.
12. ¿Qué factores consideras al diseñar e implementar esquemas de base de datos para aplicaciones a gran escala?
Al diseñar esquemas de base de datos para aplicaciones a gran escala, es importante dar prioridad a los siguientes factores:
- Requisitos funcionales: Recopilar y comprender los requisitos de la aplicación para determinar las entidades, relaciones y atributos de datos necesarios.
- Integridad y consistencia de datos: Aplicar restricciones, definir relaciones clave y garantizar la consistencia de los datos.
- Optimización de rendimiento: Optimizar la indexación, normalizar o desnormalizar las estructuras de datos y optimizar las consultas para una recuperación eficiente de datos.
- Escalabilidad y crecimiento: Diseñar el esquema para acomodar el crecimiento futuro de los datos y los requisitos de escalabilidad.
- Seguridad y control de acceso: Implementar controles de acceso adecuados, mecanismos de autenticación y cifrado de datos para garantizar la seguridad.
- Migración e integración de datos: Planificar la migración de datos, manejar cambios en el esquema e integrarse con otros sistemas o fuentes de datos.
- Normalización de datos: Buscar un nivel óptimo de normalización de datos para minimizar la redundancia y las anomalías de actualización.
- Flexibilidad y extensibilidad: Diseñar el esquema para permitir modificaciones y mejoras futuras.
13. Comparte ejemplos de cuellos de botella de rendimiento de base de datos que enfrentaste en proyectos anteriores y las medidas que tomaste para abordarlos.
Aquí hay algunos escenarios con ejemplos de respuestas, donde se implementaron diversos enfoques para ajustar el rendimiento de la base de datos para identificar y abordar cuellos de botella de rendimiento:
Optimización de consultas:
"Me encontré con una consulta de ejecución lenta que involucraba múltiples uniones y subconsultas. Para abordar esto, analicé cuidadosamente el plan de ejecución de la consulta, identifiqué operaciones ineficientes y reestructuré la consulta simplificando las uniones, eliminando subconsultas innecesarias y optimizando las condiciones. Esto mejoró significativamente el tiempo de respuesta de la consulta".
Indexación:
"En otro proyecto, noté un problema de rendimiento con una consulta que se ejecutaba con frecuencia y que involucraba tablas grandes. Después de analizar la consulta y las estructuras de tabla, identifiqué la necesidad de índices adicionales. Al crear índices adecuados en las columnas relevantes, mejoré el rendimiento de la consulta al reducir el número de operaciones de E/S en disco y permitir una recuperación más rápida de datos".
Desnormalización:
"Un escenario específico involucró un módulo de informes que requería operaciones de unión complejas en varias tablas. El rendimiento no era óptimo debido a las extensas uniones y cálculos involucrados. Desnormalicé ciertas tablas al introducir datos redundantes y agregaciones precalculadas para abordar esto. Esta desnormalización mejoró el rendimiento de la consulta de informes al eliminar la necesidad de uniones costosas y cálculos sobre la marcha".
Configuración y parámetros de la base de datos:
"Observé un rendimiento lento de la base de datos en un proyecto debido a la configuración y los valores de parámetros subóptimos. Al revisar cuidadosamente y ajustar parámetros como la asignación de memoria, los tamaños de caché de búfer y las configuraciones de paralelismo, optimicé el rendimiento de la base de datos y mejoré los tiempos de ejecución de las consultas en general".
Caché de consultas:
"Implementé mecanismos de caché de consultas para almacenar y recuperar resultados de consulta precalculados para consultas frecuentemente ejecutadas con un alto contenido de lectura".
Optimización de hardware e infraestructura:
"En una aplicación de alto tráfico, colaboré con el equipo de infraestructura para abordar los cuellos de botella de rendimiento a nivel de hardware. Identificamos oportunidades para mejorar el hardware del servidor, aumentar el rendimiento de E/S del disco y optimizar las configuraciones de red. Estas mejoras en la infraestructura impactaron positivamente en el rendimiento de la base de datos y la capacidad de respuesta del sistema en general".
14. Explica el concepto de almacenamiento de datos (data warehousing) y su importancia en inteligencia empresarial (business intelligence).
El almacenamiento de datos implica la recopilación, organización y almacenamiento de datos de diversas fuentes para la inteligencia empresarial (BI). Proporciona un repositorio centralizado para datos consolidados y estandarizados, lo que permite el análisis histórico y respalda la toma de decisiones.
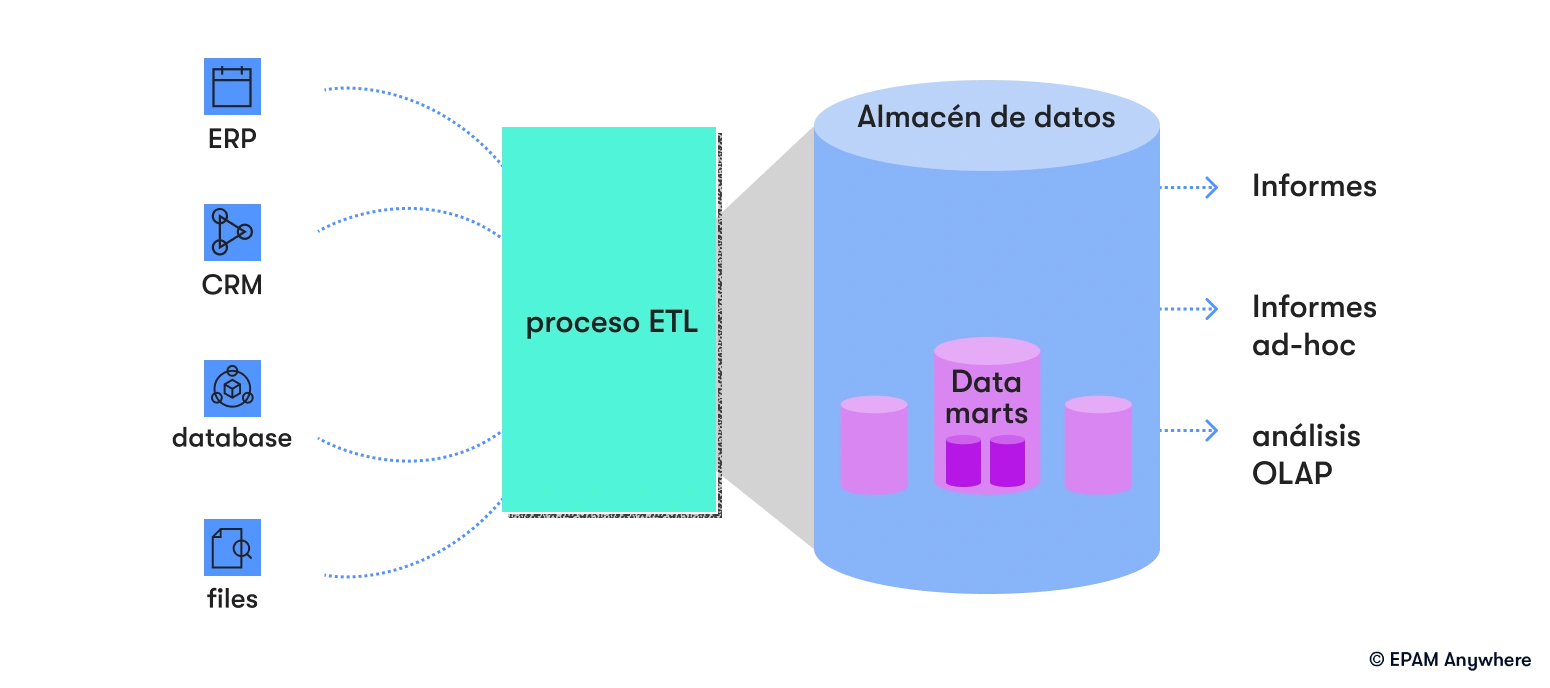
La integración y transformación de datos aseguran la precisión de los datos, mientras que el rendimiento optimizado permite realizar consultas y generar informes complejos. El almacenamiento de datos mejora la gobernanza de datos, la seguridad y la escalabilidad. Esto permite a las organizaciones extraer información, generar informes y tomar decisiones basadas en datos, impulsando el crecimiento y la competitividad del negocio.

15. Discute tu experiencia con las características de seguridad y las mejores prácticas de SQL Server.
SQL Server proporciona una variedad de características de seguridad y mejores prácticas para proteger los datos, que incluyen:
- Autenticación: Implementar mecanismos sólidos de autenticación, como la autenticación de Windows o la autenticación de SQL Server, para controlar el acceso de los usuarios.
- Autorización: Utilizar la seguridad basada en roles para otorgar permisos apropiados, siguiendo el principio del privilegio mínimo.
- Cifrado: Implementar el cifrado para proteger los datos sensibles en reposo y en tránsito contra accesos no autorizados.
- Auditoría y monitoreo: Habilitar mecanismos de auditoría y monitoreo para rastrear y detectar actividades sospechosas.
- Parches y actualizaciones: Aplicar regularmente parches de seguridad y actualizaciones para abordar vulnerabilidades.
- Configuración segura de red: Configurar cortafuegos, protocolos de red y protocolos de cifrado para asegurar la comunicación.
- Respaldo y recuperación: Implementar copias de seguridad regulares y almacenamiento seguro para garantizar la disponibilidad e integridad de los datos.


Preguntas y respuestas de la entrevista para desarrolladores de Oracle PL/SQL
Si se está preparando para una entrevista de Oracle PL/SQL, lo tenemos cubierto. Aquí hay algunas preguntas frecuentes de la entrevista, junto con sus respuestas para ayudarlo a lograr su entrevista.
16. ¿Cuál es la diferencia entre una función y un procedimiento en PL/SQL?
En PL/SQL, las funciones siempre devuelven un valor y se pueden usar en consultas SQL, mientras que los procedimientos pueden o no devolver un valor y se utilizan principalmente para ejecutar una secuencia de declaraciones. Las funciones aceptan parámetros de entrada y devuelven un valor único, mientras que los procedimientos pueden tener parámetros de entrada y/o salida, pero no tienen un valor de retorno.
Además, los procedimientos pueden realizar operaciones de manipulación de datos, mientras que las funciones no pueden modificar directamente los datos en la base de datos.
17. Explica la diferencia entre un cursor y una variable de cursor en PL/SQL.
En PL/SQL, un cursor es un objeto de base de datos utilizado para recuperar y manipular datos de conjuntos de resultados. Actúa como un puntero a una área específica de memoria que contiene los resultados de una consulta. Los cursores te permiten recorrer las filas que devuelve una consulta y realizar operaciones en ellas.
Por otro lado, una variable de cursor, también conocida como REF CURSOR, es una variable que puede contener un valor de cursor. Permite la ejecución de SQL dinámico, lo que te permite pasar referencias de cursor como parámetros o devolverlos como resultados desde funciones o procedimientos. Las variables de cursor proporcionan más flexibilidad que los cursores explícitos, ya que pueden abrirse, cerrarse y pasarse como parámetros durante el tiempo de ejecución.
18. ¿Qué son los disparadores (triggers) en Oracle PL/SQL y cuáles son sus tipos?
Los disparadores en Oracle PL/SQL son programas que se ejecutan automáticamente en respuesta a eventos como modificaciones en la base de datos o eventos a nivel del sistema. Aplican reglas, mantienen la integridad de los datos y automatizan tareas. Hay dos tipos: disparadores a nivel de fila (se activan para cada fila afectada) y disparadores a nivel de sentencia (se activan una vez por evento). Los disparadores son valiosos para aplicar restricciones, automatizar acciones e implementar lógica empresarial en la base de datos.

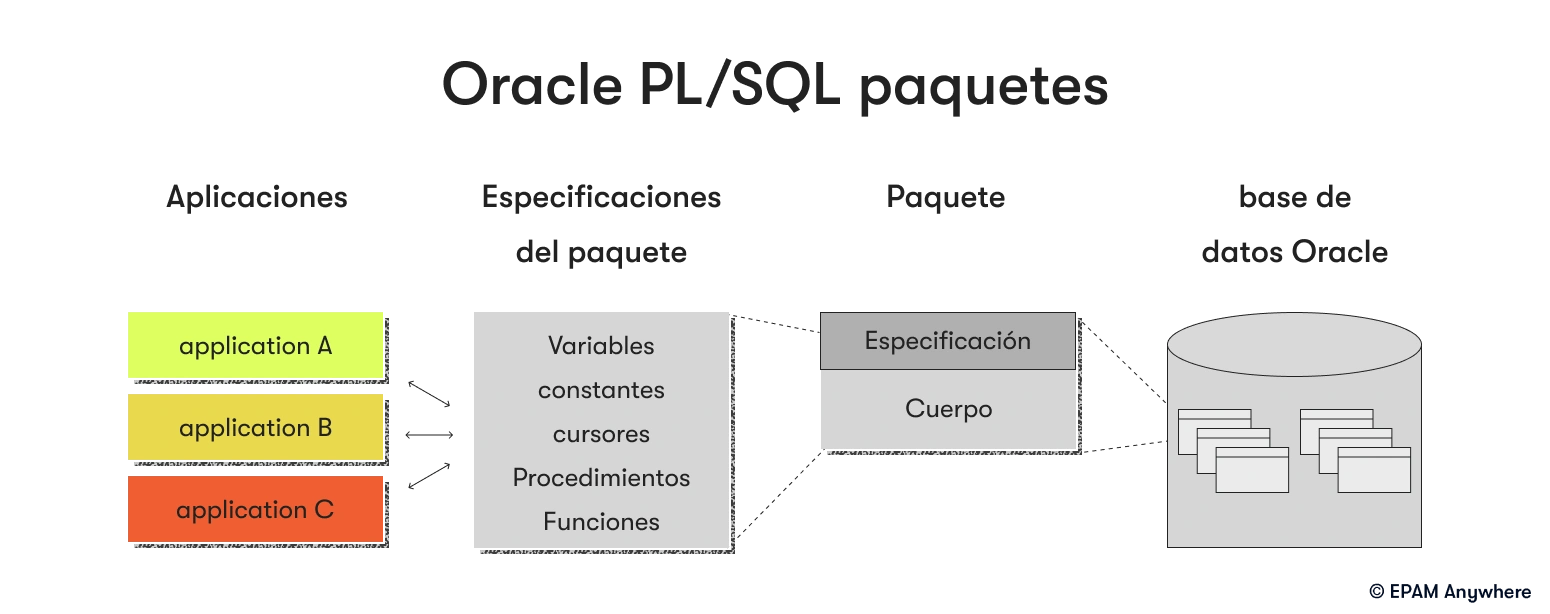
19. ¿Cuáles son las ventajas de usar paquetes PL/SQL?
Los paquetes PL/SQL proporcionan modularidad y encapsulación, lo que mejora la organización y reutilización del código. Algunas ventajas de usar paquetes PL/SQL incluyen:
- Encapsulación: Los paquetes encapsulan funciones, procedimientos, variables y cursores relacionados, proporcionando un enfoque limpio y estructurado para la organización del código.
- Reusabilidad del código: Los paquetes se pueden reutilizar en múltiples programas o aplicaciones, reduciendo la redundancia y promoviendo el intercambio de código.
- Optimización del rendimiento: Los paquetes pueden almacenar datos de acceso frecuente en variables de paquete, reduciendo la necesidad de consultas repetidas.
- Seguridad y privacidad: Los paquetes pueden restringir el acceso a procedimientos o funciones específicas, mejorando la seguridad al ocultar detalles de implementación.
20. Explica la diferencia entre las cláusulas EXCEPTION y WHEN OTHERS
En PL/SQL, las excepciones son errores o condiciones excepcionales durante la ejecución del programa. Se pueden manejar utilizando la cláusula EXCEPTION o la cláusula WHEN OTHERS. La cláusula EXCEPTION te permite definir excepciones específicas y sus manejadores correspondientes, brindando un control detallado sobre el manejo de errores.
Por otro lado, la cláusula WHEN OTHERS es una cláusula general que maneja cualquier excepción que no sea manejada explícitamente por otras cláusulas EXCEPTION. Generalmente se utiliza como opción de último recurso para asegurarse de que las excepciones no manejadas no causen la terminación abrupta del programa.
Trabajos remotos de desarrollador SQL en EPAM Anywhere
Únete a EPAM Anywhere como desarrollador SQL remoto y desbloquea infinitas oportunidades para mostrar tus habilidades y experiencia desde cualquier lugar del mundo.
Con el fuerte enfoque de EPAM en el crecimiento profesional y el aprendizaje continuo, tendrás acceso a extensos recursos y programas de capacitación para mejorar tus habilidades en el desarrollo de SQL.
Aprovecha la flexibilidad y el equilibrio entre el trabajo y la vida personal que ofrece el trabajo remoto mientras impactas significativamente en los negocios de los clientes. Únete a EPAM Anywhere hoy y prospera en un entorno dinámico e innovador donde tus talentos son valorados y cultivados.

El Equipo Editorial de EPAM Anywhere es un colectivo internacional de ingenieros de software senior, directivos y profesionales de la comunicación que crean, revisan y comparten sus puntos de vista sobre tecnología, carrera, trabajo remoto y el dia a día aquí en Anywhere.
El Equipo Editorial de EPAM Anywhere es un colectivo internacional de ingenieros de software senior, directivos y profesionales de la comunicación que crean, revisan y comparten sus puntos de vista sobre tecnología, carrera, trabajo remoto y el dia a día aquí en Anywhere.
Explora nuestra Política Editorial para conocer más sobre nuestros estándares de creación de contenido.
leer más












