




The following questions and answers have been reviewed and verified by Abhijeet Singh, Senior SQL (Oracle PL/SQL) Software Engineer at EPAM Anywhere. Thank you very much, Abhijeet!
Are you getting ready for your next technical interview? Here you’ll get a set of hand-picked SQL developer interview questions with a detailed explanation and a well-thought-out answer, providing a comprehensive understanding of the concepts.
Immersing yourself in this collection of SQL interview questions and answers will enhance your problem-solving skills, give you valuable insights into real-world SQL challenges, and improve your technical expertise.
So, let's dive in and embark on a transformative journey through the world of SQL, empowering you to ace your next interview and, who knows, even compete for a greater salary!
ready for a tech interview with us?
Send us your CV for a chance to pass a tech interview with our top certified SQL experts.
SQL developer interview questions for freshers
We have compiled a set of SQL developer interview questions tailored to freshers. These questions will help you evaluate your knowledge of basic SQL concepts, query writing, and database manipulation. By familiarizing yourself with these questions and their answers, you will gain confidence in tackling SQL interviews and showcasing your capabilities as a budding SQL developer. Let’s get into it!
1. What is SQL, and what are its key components?
SQL (Structured Query Language) is a standardized programming language for managing and manipulating relational databases. It serves as a means of communication between users and databases, allowing them to perform various tasks such as querying data, inserting or updating records, creating and modifying database structures, and controlling access to data.
The key components of SQL include:
- Data definition language (DDL): DDL statements are used to define and modify the structure of the database. They include commands like CREATE, ALTER, and DROP, which are used to create or modify tables, indexes, views, constraints, and other database objects.
- Data manipulation language (DML): DML statements are used to retrieve, insert, update, and delete data in a database. The main DML commands are SELECT, INSERT, UPDATE, and DELETE, which allow users to perform actions on the data stored in the tables.
- Data control language (DCL): DCL statements are used to manage user privileges and control access to the database. GRANT and REVOKE are the primary DCL commands, enabling the granting or revoking of permissions to users or roles.
- Transaction control language (TCL): TCL statements are used to manage transactions within a database. They include commands like COMMIT, ROLLBACK, and SAVEPOINT, which ensure data consistency and integrity by defining transaction boundaries and controlling their outcomes.
2. Differentiate between SQL's SELECT and INSERT statements
The SELECT and INSERT statements in SQL serve distinct purposes and have different functionalities. Here's a breakdown of the differences between the two:
SELECT statement
The SELECT statement retrieves data from one or more tables in a database. Its primary purpose is to query and fetch specific information based on specified conditions. The SELECT statement allows you to specify the columns you want to retrieve, apply filters using the WHERE clause, join multiple tables, perform calculations, and sort the result set. It does not modify the data in the tables; it only retrieves and presents it in the desired format.
Example: Suppose you want to retrieve the names and departments of all employees whose last names start with "Smith." The SELECT statement can be used as follows:
INSERT statement
The INSERT statement is used to insert new data into a table. It allows you to add one or more rows of data to a specified table. The INSERT statement requires you to specify the table name and provide the values or expressions for each column corresponding to the data you want to insert. It adds new records to the table, increasing its size and modifying the stored data.
Example: Assume you want to add a new employee to the "Employees" table. You have the employee's details, including their ID, first name, last name, and department. You can use the INSERT statement as follows:
In sum, while the SELECT statement retrieves and presents data from the database without modifying it, the INSERT statement adds new data into a table, thereby modifying the database by appending new records.

3. What are primary keys and foreign keys in SQL?
In SQL, primary keys and foreign keys are used to establish relationships between tables in a relational database. Here's an explanation of each:
A primary key is a column or a set of columns in a table that uniquely identifies each row in that table. It provides a way to ensure data integrity and enforce entity integrity rules. The primary key must have the following characteristics:
- It must contain unique values.
- It cannot have NULL values.
- There can only be one primary key defined per table.
Typically, the primary key is created when the table is initially designed, and it is used to identify each record in the table uniquely. Primary keys are often used as a basis for establishing relationships with other tables through foreign keys.
A foreign key is a column or a set of columns in a table that refers to the primary key of another table. It establishes a link between two tables, enforcing referential integrity and defining a relationship between them. The foreign key column in one table references the primary key column in another table.
The foreign key ensures that the values in the referencing column (foreign key column) match the values in the referenced column (primary key column). It provides a way to maintain data consistency and integrity across related tables.
4. What is the purpose of the WHERE clause in SQL queries?
The WHERE clause in SQL queries is used to filter rows from a table based on specified conditions. It allows you to retrieve only the rows that meet specific criteria, thus narrowing down the result set. The primary purpose of the WHERE clause is to selectively extract data that matches certain conditions, making the query results more meaningful and relevant.
Here's how the WHERE clause works in SQL queries:
- Filtering rows: The WHERE clause is placed after the FROM clause in a SELECT statement. It contains one or more conditions that evaluate to true or false. Rows that satisfy these conditions are included in the result set, while rows that do not meet the conditions are excluded.
- Conditional expressions: The conditions in the WHERE clause typically involve comparisons, logical operators (such as AND, OR, and NOT), and SQL functions. These conditions can be based on values in specific columns, constants, or a combination of both.
Example: Consider a table called "Employees" with columns like "EmployeeID," "FirstName," "LastName," and "Department." If you want to retrieve the details of employees working in the "Sales" department, you can use the WHERE clause as follows:
In this example, the WHERE clause filters out the rows where the "Department" column is not equal to 'Sales.' Only the rows that satisfy this condition will be included in the result set.
The WHERE clause can also be used with other SQL statements like UPDATE, DELETE, and INSERT to apply conditions when modifying or inserting data.
Overall, the WHERE clause provides a powerful mechanism for filtering data and retrieving specific subsets of rows from a table based on given conditions, enabling more precise and targeted data retrieval.
5. Describe the differences between the INNER JOIN and OUTER JOIN in SQL
In SQL, JOIN operations are used to combine rows from two or more tables based on a related column between them. The INNER JOIN and OUTER JOIN are two types of join operations with distinct characteristics. Here's a breakdown of their differences:
INNER JOIN:
- An INNER JOIN returns only the rows where there is a match between the joining columns in both tables.
- It combines rows from two or more tables based on a specified condition, called the join predicate.
- The resulting rows include only the matching records from both tables.
- If there are no matching records, the rows from both tables are excluded from the result set.
- The syntax for an INNER JOIN is as follows:
OUTER JOIN:
- An OUTER JOIN returns all the rows from one table and the matching rows from the other table(s). It includes unmatched rows as well.
- It combines rows from two or more tables based on a specified condition, just like an INNER JOIN.
- However, an OUTER JOIN includes non-matching rows by filling the missing values with NULLs.
There are three types of OUTER JOIN: LEFT OUTER JOIN, RIGHT OUTER JOIN, and FULL OUTER JOIN.
- LEFT OUTER JOIN: Returns all the rows from the left table and the matching rows from the right table(s). If there are no matches, NULL values are filled in for the columns of the right table.
- RIGHT OUTER JOIN: Returns all the rows from the right table and the matching rows from the left table(s). If there are no matches, NULL values are filled in for the columns of the left table.
- FULL OUTER JOIN: Returns all the rows from both tables, including matching and non-matching rows. If there are no matches, NULL values are filled in for the columns of the non-matching table.
- The syntax for an OUTER JOIN varies depending on the specific type of OUTER JOIN, but here's an example of a LEFT OUTER JOIN:
SQL Server developer interview questions for 5 years of experience
With 5 years of experience as an SQL Server developer, you have reached a significant milestone. As you prepare for SQL Server developer interviews at this stage, you’ll need to demonstrate your expertise in advanced topics such as database administration, performance optimization, and advanced query writing. In this section, you'll find curated SQL Server developer interview questions tailored to professionals with 5 years of experience.
6. Explain the differences between clustered and non-clustered indexes in SQL Server
In SQL Server, indexes play a crucial role in optimizing database performance by facilitating quick data retrieval. The two main types of indexes in SQL Server are clustered indexes and non-clustered indexes, and they differ in their structure and functionality. Here are the key differences:
Clustered Index:
- Structure: A clustered index determines the physical order of data rows in a table. In other words, it defines the table's physical storage order based on the indexed column(s).
- Unique: A table can have only one clustered index, as it dictates the table's physical organization.
- Data storage: The data rows in a table with a clustered index are physically stored in the order defined by the clustered index key.
- Performance impact: A well-designed clustered index can enhance query performance for range-based searches or when retrieving large portions of data. However, it may slow down data modification operations (such as INSERT, UPDATE, and DELETE) as the physical order needs to be adjusted.
Non-clustered index:
- Structure: A non-clustered index creates a separate structure that includes the indexed column(s) and a pointer to the actual data rows.
- Multiple indexes: A table can have multiple non-clustered indexes, allowing for different indexing strategies based on query requirements.
- Data storage: The data rows in a table with a non-clustered index are stored separately from the index structure. The index structure contains a copy of the indexed column(s) and a pointer to the corresponding data row.
- Performance impact: Non-clustered indexes are beneficial for improving query performance by allowing quick data lookup based on the indexed column(s). They generally have minimal impact on data modification operations.
7. What types of replication are available in SQL Server, and when would you use each?
In SQL Server, three main types of replication are available: snapshot replication, transactional replication, and merge replication. Each type serves specific purposes and is used in different scenarios. Here's an overview of each replication type and their typical use cases:
Snapshot replication
This involves taking a snapshot of the replicated database and copying it to the subscriber(s). Subsequent changes to the publisher database are not propagated to the subscribers automatically. Instead, a new snapshot needs to be generated and applied to the subscribers to synchronize the data.
Use cases:
- Infrequently changing data: Snapshot replication is suitable when the data changes infrequently, and near real-time synchronization is not required.
- Reporting or data distribution: It can be used for distributing static data or creating read-only copies of a database for reporting purposes.
Transactional replication
Transactional replication captures and replicates individual data modifications, such as inserts, updates, and deletes, as transactions occur on the publisher database. The transactions are then applied to the subscriber(s) in the same order they occurred.
Use cases:
- Real-time data synchronization: Transactional replication is ideal when you need near real-time data synchronization between the publisher and subscribers.
- High transaction volume: It is commonly used in scenarios with high volumes of transactions, such as online transaction processing (OLTP) systems.
Merge replication
Merge replication is a bidirectional replication method that allows changes to be made at both the publisher and subscriber databases. It tracks and reconciles the changes made at each replica and resolves conflicts that may arise when the same data is modified at multiple locations.
Use cases:
- Mobile or offline scenarios: Merge replication is well-suited for scenarios where disconnected or occasionally connected clients need to synchronize data with the central server.
- Collaborative environments: It is commonly used in environments where multiple users or teams must work on the same data set and require bidirectional synchronization.
8. How would you optimize a slow-performing query in SQL Server?
To optimize a slow-performing query in SQL Server, follow these steps:
- Analyze the query execution plan for potential issues.
- Use appropriate indexing to improve query performance.
- Retrieve only necessary columns and rows to minimize data retrieval.
- Optimize join conditions and types for efficient data retrieval.
- Simplify complex queries by breaking them into smaller parts.
- Update table and index statistics for accurate query optimization.
- Tune server configuration settings based on hardware and workload.
- Consider query rewriting or caching to improve performance.
- Monitor and optimize I/O performance.
- Keep SQL Server updated and maintain the database regularly.
9. Describe the ACID properties in the context of SQL Server transactions
The ACID properties in SQL Server transactions ensure reliability and data integrity:
- Atomicity: Transactions are treated as a single unit of work. Either all operations are successfully completed and committed, or none of them are, preventing incomplete or inconsistent data.
- Consistency: Transactions bring the database from one valid state to another, enforcing predefined rules and constraints. Violations result in rollback to maintain data consistency.
- Isolation: Concurrent transactions are isolated from each other to prevent interference and ensure data integrity. Isolation levels define the trade-off between concurrency and consistency.
- Durability: Committed transactions are permanently stored, surviving system failures. Data is securely stored and recoverable, providing reliability.
These properties maintain SQL Server transactions' reliability, consistency, and integrity, supporting critical business operations.
10. How would you handle database schema changes in a production environment without causing downtime?
To handle database schema changes in a production environment without downtime:
- Plan and document changes carefully.
- Use version control to track and manage schema changes.
- Test changes in a non-production environment.
- Implement blue-green deployment to switch to the updated schema seamlessly.
- Utilize database migration tools for controlled deployment.
- Schedule changes during maintenance windows or low-traffic periods.
- Use online schema changes or tools designed for minimal downtime.
- Have a rollback plan in case of issues.
boost your career with EPAM Anywhere
Apply for our SQL developer job to enjoy a forever-remote workstyle and top projects for Forbes Global 2000 clients.
SQL developer interview questions for 10 years of experience
In this section, we present SQL developer interview questions tailored to people with 10 years of experience. These questions assess the candidate's in-depth knowledge and expertise in SQL development, database design, optimization, and advanced SQL concepts.
11. Explain the concept of query optimization in SQL with examples
SQL query optimization aims to improve query performance by selecting the most efficient execution plan. The following techniques are commonly used to optimize complex queries:
- Analyzing execution plans: Identify bottlenecks and inefficiencies in query execution plans.
- Indexing strategies: Create or modify indexes based on filtering and sorting requirements.
- Simplify queries: Break complex queries into smaller parts, eliminate unnecessary joins, and optimize conditions.
- Partitioning: Divide large tables into smaller partitions to improve data access and parallelism.
- Caching and materialized views: Utilize caching mechanisms and precomputed views to reduce computation time.
- Query tuning: Rewrite suboptimal queries, adjust join strategies, and optimize query parameters.
- Parameter optimization: Fine-tune system resources and configuration settings.
- Regular maintenance: Update statistics, rebuild indexes, and remove unnecessary data.
12. What factors do you consider when designing and implementing database schemas for large-scale applications?
When designing database schemas for large-scale applications, prioritize the following factors:
- Functional requirements: Gather and understand the application's requirements to determine the entities, relationships, and data attributes needed.
- Data integrity and consistency: Enforce constraints, define key relationships, and ensure data consistency.
- Performance optimization: Optimize indexing, normalize or denormalize data structures, and optimize queries for efficient data retrieval.
- Scalability and growth: Design the schema to accommodate future data growth and scalability requirements.
- Security and access control: Implement proper access controls, authentication mechanisms, and data encryption to ensure security.
- Data migration and integration: Plan for data migration, handle schema changes, and integrate with other systems or data sources.
- Data normalization: Strive for an optimal level of data normalization to minimize redundancy and update anomalies.
- Flexibility and extensibility: Design the schema to allow for future modifications and enhancements.
13. Share examples of database performance bottlenecks you faced on past projects and the steps you took to address them
Here are a few scenarios with sample answers, where various approaches are implemented for database performance tuning to identify and address performance bottlenecks:
Query optimization
“I encountered a slow-performing query that involved multiple joins and subqueries. To address this, I carefully analyzed the query execution plan, identified inefficient operations, and restructured the query by simplifying joins, eliminating unnecessary subqueries, and optimizing conditions. This significantly improved the query's response time.”
Indexing
“In another project, I noticed a performance issue with a frequently executed query that involved large tables. After analyzing the query and table structures, I identified the need for additional indexes. By creating appropriate indexes on the relevant columns, I improved the query's performance by reducing the number of disk I/O operations and enabling faster data retrieval.”
Denormalization
“A specific scenario involved a reporting module that required complex join operations across multiple tables. The performance was suboptimal due to the extensive joins and calculations involved. I denormalized certain tables by introducing redundant data and pre-calculated aggregations to address this. This denormalization improved the reporting query performance by eliminating the need for expensive joins and calculations on the fly.”
Database configuration and parameters
“I observed slow database performance in one project due to suboptimal configuration settings and parameter values. By carefully reviewing and adjusting parameters like memory allocation, buffer cache sizes, and parallelism settings, I optimized the database performance and improved overall query execution times.”
Query caching
“I implemented query caching mechanisms to store and retrieve precomputed query results for frequently executed read-heavy queries. By leveraging technologies like memcached and Redis, I reduced the load on the database server and improved the overall application response time.”
Hardware and infrastructure optimization
“In a high-traffic application, I collaborated with the infrastructure team to address performance bottlenecks at the hardware level. We identified opportunities to upgrade server hardware, increase disk I/O throughput, and optimize network configurations. These infrastructure improvements positively impacted database performance and overall system responsiveness.”
14. Explain the concept of data warehousing and its importance in business intelligence
Data warehousing involves collecting, organizing, and storing data from various sources for business intelligence (BI). It provides a centralized repository for consolidated and standardized data, enabling historical analysis and supporting decision-making.
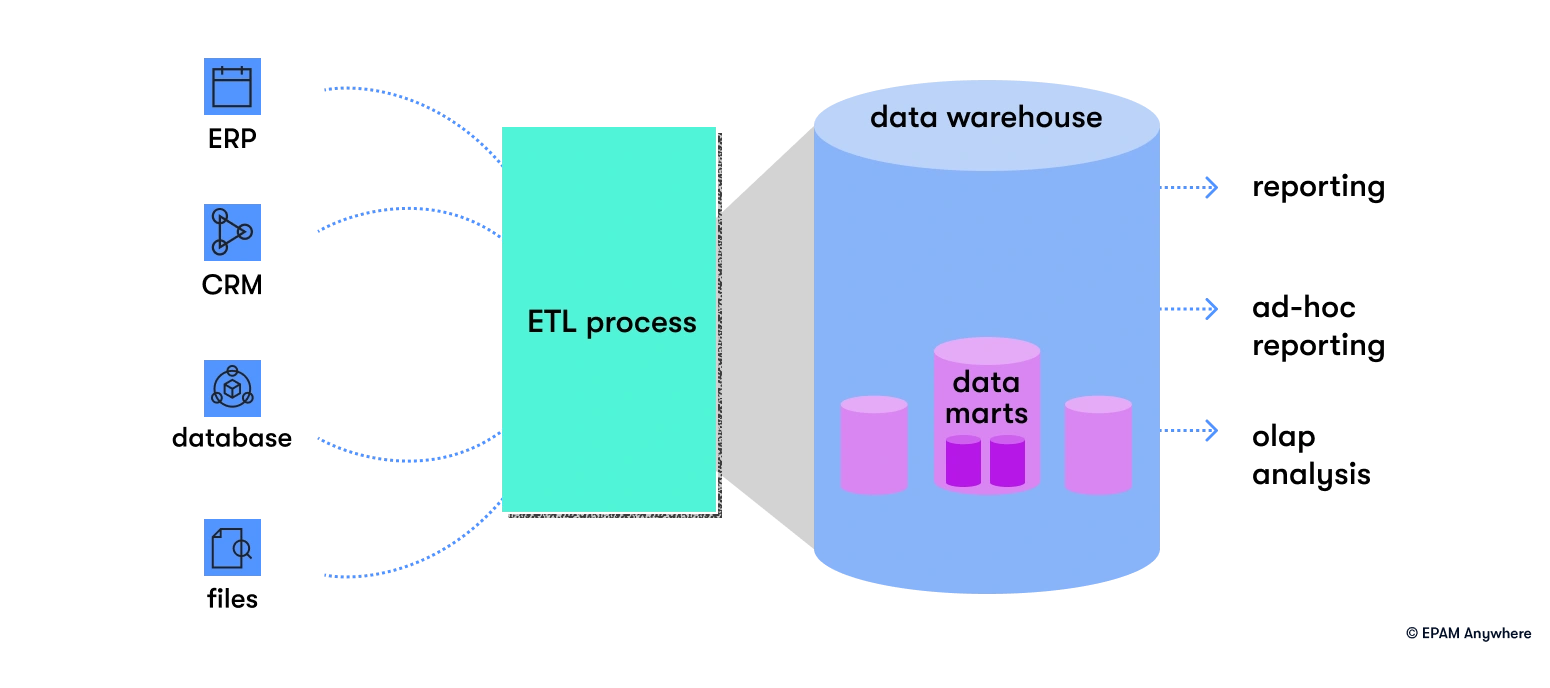
Data integration and transformation ensure data accuracy, while optimized performance allows for complex queries and reporting. Data warehousing enhances data governance, security, and scalability. It empowers organizations to extract insights, generate reports, and make data-driven decisions, driving business growth and competitiveness.

15. Discuss your experience with SQL Server security features and best practices
SQL Server provides a range of security features and best practices to protect data, including:
- Authentication: Implement strong authentication mechanisms like Windows Authentication or SQL Server Authentication to control user access.
- Authorization: Use role-based security to grant appropriate permissions, following the principle of least privilege.
- Encryption: Implement encryption for sensitive data at rest and in transit to protect against unauthorized access.
- Auditing and monitoring: Enable auditing and monitoring mechanisms to track and detect suspicious activity.
- Patching and updates: Regularly apply security patches and updates to address vulnerabilities.
- Secure network configuration: Configure firewalls, network protocols, and encryption protocols to secure communication.
- Backup and recovery: Implement regular backups and secure storage to ensure data availability and integrity.


Oracle PL/SQL developer interview questions and answers
If you’re getting ready for an Oracle PL/SQL interview, we’ve got you covered. Here are a few commonly asked interview questions, along with their answers to help you nail your interview.
16. What is the difference between a function and a procedure in PL/SQL?
In PL/SQL, functions always return a value and can be used in SQL queries, while procedures may or may not return a value and are primarily used for executing a sequence of statements. Functions accept input parameters and return a single value, whereas procedures can have input and/or output parameters but do not have a return value.
Additionally, procedures can perform data manipulation operations, while functions cannot directly modify data in the database.
17. Explain the difference between a cursor and a cursor variable in PL/SQL
In PL/SQL, a cursor is a database object used to retrieve and manipulate data from result sets. It acts as a pointer to a specific area of memory that holds query results. Cursors allow you to iterate over the rows a query returns and perform operations on them.
On the other hand, a cursor variable, also known as a REF CURSOR, is a variable that can hold a cursor value. It allows dynamic SQL execution, enabling you to pass cursor references as parameters or return them as results from functions or procedures. Cursor variables provide more flexibility than explicit cursors because they can be opened, closed, and passed around as parameters during runtime.
18. What are triggers in Oracle PL/SQL, and what are their types?
Triggers in Oracle PL/SQL are programs that automatically execute in response to events like database modifications or system-level events. They enforce rules, maintain data integrity, and automate tasks. There are two types: row-level triggers (fire for each affected row) and statement-level triggers (fire once per event). Triggers are valuable for enforcing constraints, automating actions, and implementing business logic in the database.

19. What are the advantages of using PL/SQL packages?
PL/SQL packages provide modularity and encapsulation, which improves code organization and reusability. Some advantages of using PL/SQL packages include:
- Encapsulation: Packages encapsulate related functions, procedures, variables, and cursors, providing a clean and structured approach to code organization.
- Code reusability: Packages can be reused across multiple programs or applications, reducing redundancy and promoting code sharing.
- Performance optimization: Packages can store frequently accessed data in package variables, reducing the need for repeated queries.
- Security and privacy: Packages can restrict access to specific procedures or functions, enhancing security by hiding implementation details.
20. Explain the difference between the EXCEPTION and WHEN OTHERS clauses
In PL/SQL, exceptions are errors or exceptional conditions during program execution. They can be handled using the EXCEPTION clause or the WHEN OTHERS clause. The EXCEPTION clause allows you to define specific exceptions and their corresponding handlers, providing fine-grained control over error handling.
On the other hand, the WHEN OTHERS clause is a catch-all clause that handles any exception not explicitly handled by other EXCEPTION clauses. It is generally used as a fallback option to ensure that unhandled exceptions do not cause the program to terminate abruptly.
Remote SQL developer jobs at EPAM Anywhere
Join EPAM Anywhere as a remote SQL developer and unlock endless opportunities to showcase your skills and expertise from anywhere in the world.
With EPAM's strong focus on professional growth and continuous learning, you'll have access to extensive resources and training programs to enhance your SQL development skills.
Take advantage of the flexibility and work-life balance offered by remote work while significantly impacting clients' businesses. Join EPAM Anywhere today and thrive in a dynamic, innovative environment where your talents are valued and nurtured.

As Chief Editor, Darya works with our top technical and career experts at EPAM Anywhere to share their insights with our global audience. With 12+ years in digital communications, she’s happy to help job seekers make the best of remote work opportunities and build a fulfilling career in tech.
As Chief Editor, Darya works with our top technical and career experts at EPAM Anywhere to share their insights with our global audience. With 12+ years in digital communications, she’s happy to help job seekers make the best of remote work opportunities and build a fulfilling career in tech.
Explore our Editorial Policy to learn more about our standards for content creation.
read more












