






The Snowflake Inc. company disrupted the world of data analytics with its same-name platform. They launched their renowned solution in 2012. Since then, the Snowflake platform has received numerous updates and functionality to become a robust and safe data platform.
Prerequisites
One of the clients at EPAM reached out to us with a request to develop a complex analytics platform for its end-clients. Its vital features included self-service data discovery, dashboards, and real-time data connections.
Architectural solutions
Not all source systems we needed to integrate our system with, allowed us to extract the data in real-time. Our task was to design a solution that would combine batch and streaming data pipelines. On top of that, our core technologies were Snowflake and Tableau.
Snowflake is a key technology for the analytical system, but it required extra tools to help us build a full-fledged platform.
Another requirement was to use the AWS cloud as a hosting platform. Considering all of those conditions, we came up with a solution similar to Lambda Architecture.
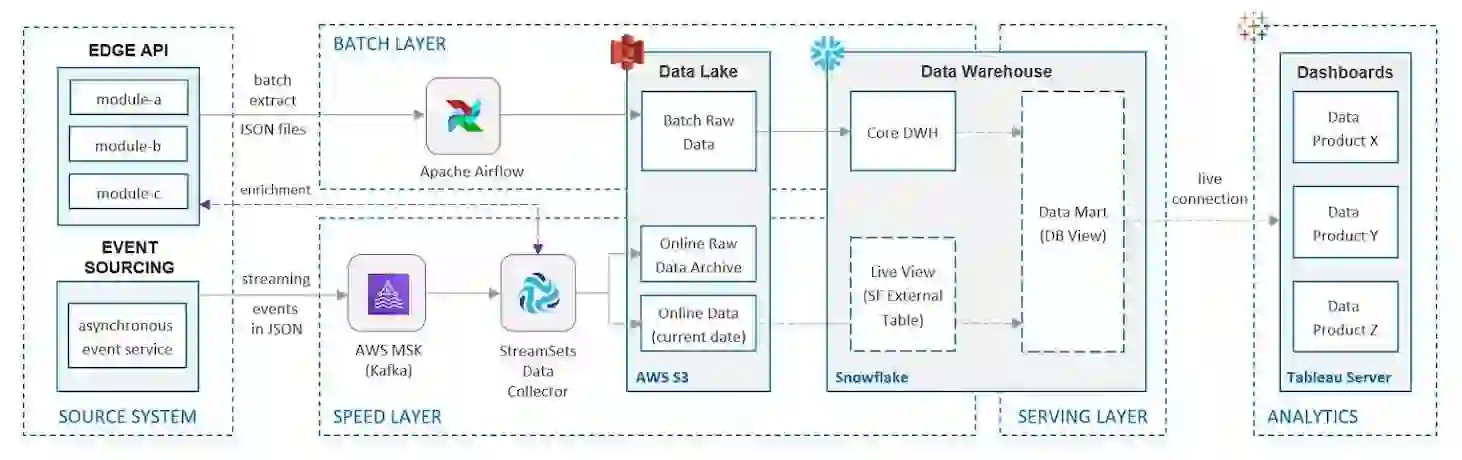
On a high level, the architecture consists of the following layers:
- The BATCH LAYER retrieves and transforms the data, using APIs of source systems. This layer helps fix errors, synchronize the data with other third-party systems, and conduct data quality checks. The processed data is stored in Snowflake in Core DWH and Data Mart layers and replaces online data from the previous day.
- The SPEED LAYER processes data streams from a source system in near real-time. This layer minimizes latency by providing real-time views into the most recent data. Thus, views in this layer may have more inaccuracies than in the batch layer. However, those inaccuracies are daily replaced once the batch layer’s views for the same data become available.
- The SERVING LAYER combines the data from the batch and speed layers through Snowflake DB view and responds to ad-hoc queries from Tableau's end-users.
Implementation details
Now let's overview the implementation of the end-to-end data pipeline.
Batch data ingestion and processing
Here's the step-by-step data workflow:
- Data ingestion. First, the data is ingested from a source system into the Data Lake (AWS S3) through the source system API. Python scripts are triggered using Apache Airflow that serves as an orchestrator tool for the entire batch pipeline. Amazon Elastic Kubernetes Service (EKS) is leveraged to run Airflow workload.
- Landing to Snowflake. Raw (As Is) data from the Data Lake is copied into the Snowflake Landing area. To implement this operation, Snowflake Virtual Warehouse executes Snowflake copy commands triggered by Apache Airflow.
- Transformation into Core DWH layer. Raw data from the Snowflake Landing area is transformed into the Core DWH layer with the canonical domain data model (Data Vault modeling is leveraged here). Apache Airflow triggers SQL scripts executed on a Snowflake Virtual Warehouse to process the data.
- Transformation into Data Mart layer. Data from the Core DWH layer is transformed into data marts (dimensional modelling) according to specific business requirements. Depending on the transformation complexity, software engineers can stick to two options:
- Virtual data marts using Snowflake DB views. In this case, we don't store the data physically.
- Persistent Snowflake tables. Apache Airflow triggers SQL scripts that are executed on a Snowflake Virtual Warehouse, and the scripts calculate business rules and write the information into the data mart tables.
Near real-time processing of data pipeline (Speed Layer)
As part of the speed layer, the data goes through the following steps:
- The source system’s asynchronous event service acts as a filter to capture traffic from the source system as JSON messages. Then it routes the messages to Amazon MSK (managed Kafka) topics.
- StreamSets Data Collector (SDC) tool is used to consume events from Kafka topics and process them:
- Filters required JSON messages
- Enriches the data on the fly using the source system API (for instance, gets an entity name by passing its ID)
- Applies other required transformations to the data (data masking, filtering, etc.)
- Converts the data into CSV file format and puts the file into Data Lake S3 folder — Online Data (current date) on the diagram
- In parallel, filtered original JSON messages are put into the Data Lake S3 folder — Online Raw Data Archive.
- A Snowflake external table (Live View on the diagram) allows us to query the information directly from the Data Lake S3 bucket. Thus, the data is not stored in the database but only passes through a Snowflake Virtual Warehouse when queried from the Tableau server.
Serving Layer
The serving layer is implemented as a set of Snowflake DB views that combine the information from data marts (prepared in the batch dataflow) and the Snowflake external tables (Live View on the diagram). As a result, the actual data is ready for consumption from the Tableau server through customized dashboards and self-service data discovery capability. Using Live Connection mode, the Tableau server makes queries directly against Snowflake DB.
Alternative options for implementing near real-time analytics with Snowflake
If you have experience with Snowflake, you might be wondering why we didn't use Snowpipe to implement continuous data loading into the database. Snowpipe enables loading data in micro-batches from files as soon as they are available in a stage and makes it available to users within minutes. Our requirement was to decrease this time frame to seconds.
Also, with Snowpipe’s serverless compute model, Snowflake manages load capacity, ensuring optimal resources to meet demand, but you have to pay for it. In the case of external tables, we do not load data into Snowflake (it is stored in an S3 bucket) and, accordingly, we do not need to pay for data loading.
Keep in mind that as files with new events are added to S3, the external tables must be refreshed (alter external table … refresh).
Wrapping up
As organizations are becoming more data-driven, business requirements are becoming more complicated.
For instance, lately, we've been seeing a trend for near real-time processing. This demand pushes software engineers to search for cutting-edge technologies like Snowflake. In this post, we shared our successful experience with Snowflake to implement near real-time analytics.



Explore our Editorial Policy to learn more about our standards for content creation.
read more














