The following article has been reviewed and verified by Juliana Diaz, Senior Software Engineer (Data Analytics & Visualization) at EPAM Anywhere. Many thanks, Juliana!
Looking to land a data engineering role? Preparation is key, and that starts with familiarizing yourself with common technical interview questions. In this article, we've compiled a list of 12 essential data engineer interview questions along with their answers to help you ace your next interview.
From data integration and processing to cloud-based technologies and data governance, these questions cover various topics from data engineer basic interview questions to more advanced ones to assess your technical skills and problem-solving abilities. Whether you're a seasoned specialist or just starting your career as a data engineer, mastering these interview questions will boost your confidence and increase your chances of success in the competitive field of data engineering.
apply for a data engineer job with EPAM Anywhere
No need to browse job posts anymore. Send us your CV and our recruiters will get back to you with the best-matching job.
1. Describe the experience of designing and developing data pipelines.
Data engineer basic interview questions like this serve as an excellent starting point to gauge a candidate's familiarity with essential data engineering principles and their ability to apply them in practical scenarios.
Designing and developing data pipelines is crucial to a data engineer's role. It involves collecting, transforming, and loading data from various sources into a destination where it can be analyzed and utilized effectively. Here's a breakdown of the key components involved in this process:
- Data source identification: Understanding the sources of data and their formats is essential. This can include databases, APIs, log files, or external data feeds.
- Data extraction: Extracting data from the identified sources using appropriate extraction methods such as SQL queries, web scraping, or API calls.
- Data transformation: Applying transformations to the extracted data to ensure it is in a consistent, clean, and usable format. This may involve data cleansing, normalization, aggregation, or enrichment.
- Data loading: Loading the transformed data into a destination system, which could be a data warehouse, a data lake, or a specific analytical database.
- Pipeline orchestration: Managing the overall flow and execution of the data pipeline. This may involve scheduling jobs, monitoring data quality, handling error scenarios, and ensuring data consistency and reliability.
- Scalability and performance optimization: Designing the pipeline to handle large volumes of data efficiently and optimizing performance through parallel processing, partitioning, and indexing.
- Data quality and monitoring: Implementing measures to ensure data quality, including data validation, anomaly detection, and error handling. Monitoring the pipeline for failures, latency issues, or any other abnormalities is also crucial.
- Maintenance and iteration: Regularly reviewing and updating the data pipeline to accommodate changing data sources, business requirements, and emerging technologies. This includes incorporating feedback, making enhancements, and troubleshooting issues.
A data engineer's experience in designing and developing data pipelines encompasses a deep understanding of data integration, data modeling, data governance, and the tools and technologies involved, such as ETL frameworks, workflow schedulers, and cloud platforms. Additionally, familiarity with programming languages like Python and SQL and knowledge of distributed computing frameworks like Apache Spark can significantly contribute to building efficient and scalable data pipelines.

2. How do you integrate data from multiple sources?
Here are some key steps and considerations for effectively integrating data from multiple sources:
- Identify data sources: Identify the various sources from which data needs to be integrated. This can include databases, APIs, file systems, streaming platforms, external data feeds, or even legacy systems.
- Understand data formats and structures: Gain a deep understanding of the formats and structures of the data sources. This includes knowing whether the data is structured, semi-structured (e.g., JSON, XML), or unstructured (e.g., text, images), and the schema or metadata associated with each source.
- Data extraction: Extract data from the identified sources using appropriate methods. This can involve techniques such as SQL queries, web scraping, API calls, log parsing, or message queue consumption, depending on the specific source and its accessibility.
- Data transformation: Transform the extracted data into a common format or schema that can be easily integrated. This may involve data cleaning, normalization, deduplication, or standardization. Mapping data fields between different sources might be necessary to ensure consistency.
- Data integration: Integrate the transformed data from different sources into a unified data model or destination system. This can be done using ETL (extract, transform, load) processes, data integration tools, or custom scripts.
- Data mapping and joining: Define the relationships and mappings between data elements from different sources. This may involve identifying key identifiers or common attributes to join and consolidate data accurately.
- Data quality assurance: Implement data quality checks and validation processes to ensure the accuracy, completeness, and consistency of the integrated data. This may involve verifying data types, range checks, uniqueness, and referential integrity.
- Data governance and security: Consider data governance practices, such as access controls, data masking, and encryption, to protect sensitive data during the integration process.
- Incremental data updates: Establish mechanisms to handle incremental data updates from the various sources. This includes tracking changes, managing data versioning, and efficiently processing only the updated or new data to minimize processing overhead.
- Monitoring and error handling: Implement monitoring mechanisms to track the health and performance of data integration processes. Set up alerts and error handling mechanisms to identify and resolve issues promptly.
- Scalability and performance optimization: Design the integration process to handle large volumes of data efficiently. This may involve techniques like parallel processing, partitioning, caching, or using distributed computing frameworks.
- Documentation: Document the data integration process, including data source information, transformation rules, data mappings, and any relevant considerations. This documentation helps maintain the integration solution and facilitates knowledge sharing within the team.

Remember, the specific approach to integrating data from multiple sources may vary depending on the project requirements, available resources, and technology stack. A well-designed data integration strategy ensures data consistency, accuracy, and availability for downstream applications, reporting, and analysis.
3. What data visualization tools have you used for reporting and analysis?
Here is a list of commonly used data visualization tools for reporting and data analysis:
- Tableau: Tableau is a widely-used data visualization tool that allows users to create interactive dashboards, reports, and visualizations. It offers a user-friendly interface and supports a variety of data sources.
- Power BI: Power BI, developed by Microsoft, is another popular tool for data visualization and business intelligence. It offers a range of visualization options, data connectors, automation practices, and integration with other Microsoft products.
- QlikView: QlikView provides interactive and dynamic data visualization capabilities. It allows users to create associative data models, perform ad-hoc analysis, and build visually appealing dashboards.
- Looker: Looker is a platform that combines data exploration, visualization, and embedded analytics. It enables users to build custom dashboards and explore data in a collaborative environment.
- D3.js: D3.js (Data-Driven Documents) is a JavaScript library for creating custom and highly interactive visualizations. It provides a powerful set of tools for data manipulation and rendering visual elements based on data.
- Google Data Studio: Google Data Studio is a free tool for creating interactive dashboards and reports. It integrates with various Google services and allows easy sharing and collaboration.
- Plotly: Plotly is a flexible and open-source data visualization library available for multiple programming languages. It offers a wide range of chart types and allows customization of visualizations.
- Grafana: Grafana is a popular open-source tool used for real-time analytics and monitoring. It supports various data sources and provides customizable dashboards and panels.
- Apache Superset: Apache Superset is an open-source data exploration and visualization platform. It provides a rich set of interactive visualizations, dashboards, and SQL-based querying.
- Salesforce Einstein Analytics: Salesforce Einstein Analytics is a cloud-based analytics platform that enables users to create visualizations, explore data, and gain insights within the Salesforce ecosystem.
- MATLAB: MATLAB is a programming and analysis environment that includes powerful data visualization capabilities for scientific and engineering applications.

4. How do you use data to drive improved business decisions?
Data-driven decision-making involves leveraging data, analyzing it for insights, and incorporating those insights into the decision-making process. By following these steps, you can improve decision-making, track progress, and achieve better outcomes:
- Collect the right data. Start by collecting the right data that is applicable to the decisions you are trying to make. Be sure to collect as much quantitative data as you can based on the questions you have.
- Develop an analytical framework. Develop an analytical framework to evaluate the data and set key performance indicators (KPIs) for evaluating the data against the decision-making process. Make sure to clearly define success for the analysis.
- Analyze and interpret the data. Using the analytical framework, analyze and interpret the data to glean meaningful insights for decision-making.
- Apply the data. Apply the data to inform decision-making processes and identify areas of improvement.
- Monitor and track performance. Monitor and track performance to ensure that you are making decisions based on the best data-driven insights available.
5. Explain the difference between batch processing and real-time streaming. When would you choose one over the other in a data engineering project?
Batch processing involves collecting large amounts of data over a period of time and then submitting it to a system for processing in large chunks. This method is typically used for analyzing and processing more static and historical data.
Real-time streaming involves continuously collecting and analyzing data in small chunks as it arrives in real-time. This method is typically used for exploring data sets that are dynamic and up to date.
Which approach you should use for a data engineering project depends on the nature of the data and the results you are seeking. Real-time streaming may be the best option if you need an up-to-date analysis for forecasting or predicting outcomes. However, if you need to build a model based on data collected over a period of time and its long-term trends, then batch processing can be more helpful.
try a tech interview with us
Send us your resume and get invited to a technical interview for one of our available jobs matching your profile.
6. Describe your experience working with cloud-based data storage and processing platforms (e.g., AWS, GCP, Azure). Which services have you utilized and what benefits did they provide?
Platforms such as AWS (Amazon Web Services), GCP (Google Cloud Platform), and Azure (Microsoft Azure) provide a range of services for data storage, processing, and analytics. Here are some commonly utilized services within these platforms and their benefits:
- Amazon S3 (Simple Storage Service): S3 is an object storage service that provides scalable, durable, and secure storage for various types of data. It offers high availability, data encryption, and easy integration with other AWS services, making it a reliable choice for storing large volumes of data.
- Google Cloud Storage: Similar to Amazon S3, Google Cloud Storage provides secure and scalable object storage with features like data encryption, versioning, and global accessibility. It integrates well with other GCP services and offers options for multi-regional, regional, and nearline storage.
- Azure Blob Storage: Azure Blob Storage is a scalable and cost-effective object storage solution. It offers tiered storage options, including hot, cool, and archive tiers, allowing users to optimize costs based on data access frequency. Blob Storage also provides encryption, versioning, and seamless integration with other Azure services.
- AWS Glue: Glue is an ETL service that simplifies the process of preparing and transforming data for analytics. It offers automated data cataloging, data cleaning, and data transformation capabilities, reducing the time and effort required for data preparation.
- Google BigQuery: BigQuery is a serverless data warehouse and analytics platform. It enables users to analyze large datasets quickly with its scalable infrastructure and supports SQL queries and machine learning capabilities. BigQuery's pay-per-query pricing model and seamless integration with other GCP services make it a powerful analytics solution.
- Azure Data Lake Analytics: Azure Data Lake Analytics is a distributed analytics service that can process massive amounts of data using a declarative SQL-like language or U-SQL. It leverages the power of Azure Data Lake Storage and provides on-demand scalability for big data analytics workloads.
- AWS EMR (Elastic MapReduce): EMR is a managed cluster platform that simplifies the processing of large-scale data using popular frameworks such as Apache Hadoop, Spark, and Hive. It allows for easy cluster management, autoscaling, and integration with other AWS services.
The benefits of utilizing these platforms include scalability, cost-effectiveness, flexibility, reliability, and the ability to leverage a wide range of services and integrations. They provide a robust infrastructure for storing and processing data, enabling organizations to focus on data analytics, insight generation, and innovation without the burden of managing complex infrastructure.
7. How do you handle data security and privacy concerns within a data engineering project?
Handling data security and privacy concerns is crucial in any data engineering project to protect sensitive information and ensure compliance with relevant regulations. To do this, the following practices should be implemented:
- Create a data security and privacy policy and assess the level of compliance by all data engineering project participants.
- Store data within secure and private environments, including appropriate network and firewall configurations, end-user authentication, and access control.
- Utilize encryption when transferring and storing sensitive data.
- Authenticate and authorize access to restricted data.
- Use non-disclosure agreements (NDAs) to protect confidential company information.
- Ensure all contributing parties comply with applicable data privacy laws and regulations.
- Regularly monitor systems and networks for suspicious activity.
- Educate workers on best security practices.
- Perform regular security and privacy audits.
- Regularly back up data and backtest models.

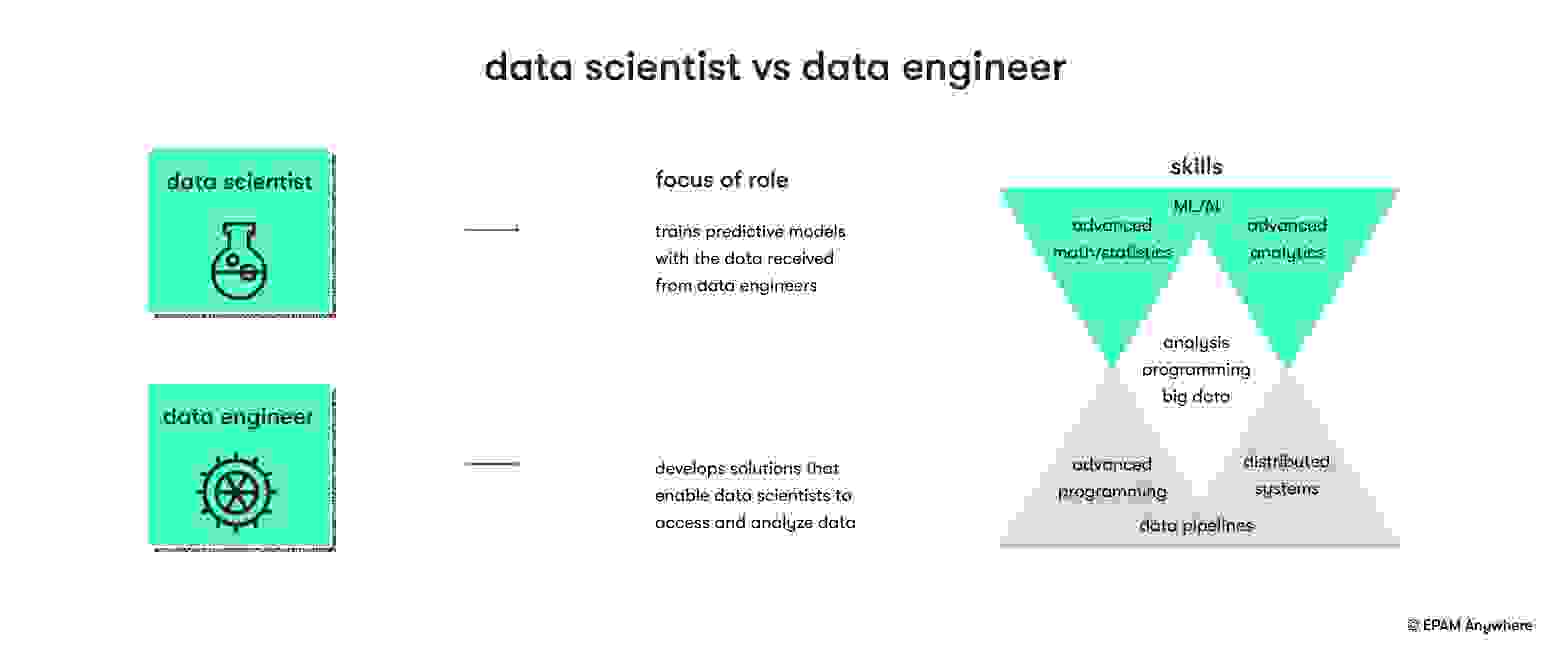
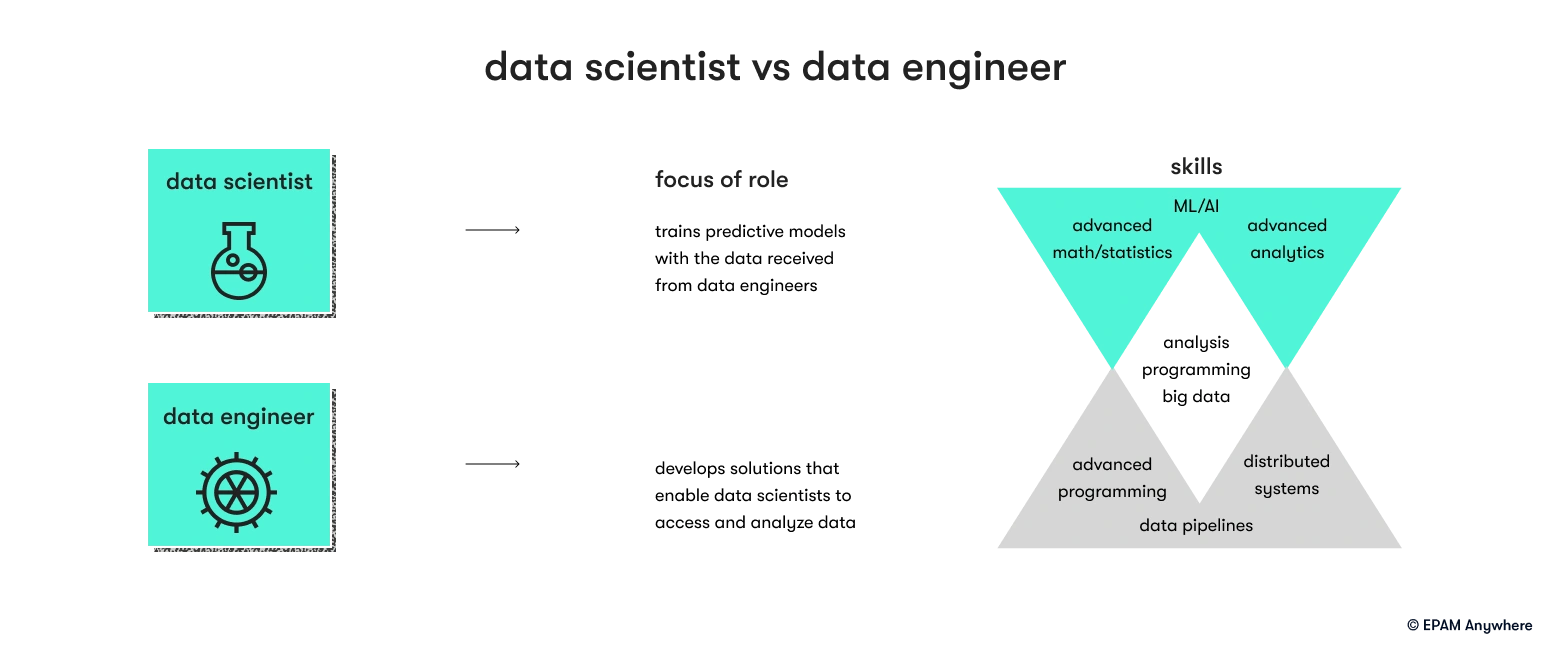
8. What is the difference between a data engineer and a data scientist?
A data engineer focuses on designing and maintaining data infrastructure and systems for efficient data processing, storage, and integration. They handle data pipelines, databases, and data warehouses.
A data scientist focuses on analyzing data, extracting insights, and building models for predictive analysis and decision-making. They apply statistical techniques, develop machine learning models, and communicate findings to stakeholders.
9. Can you explain the concept of data partitioning and how it helps with data processing efficiency?
Data partitioning is a technique used in data processing to divide a large dataset into smaller, more manageable segments called partitions. Each partition contains a subset of the data that is logically related or has a common attribute.
By partitioning data, it becomes easier to process and analyze large volumes of data efficiently. Here's how data partitioning helps with data processing efficiency:
- Improved query performance: Partitioning enables parallel processing of data across multiple nodes or processing units. Queries and computations can be executed simultaneously on different partitions, leading to faster query response times and improved overall performance.
- Reduced data scanning: With data partitioning, the system can perform selective scanning by accessing only relevant partitions instead of scanning the entire dataset. This reduces the amount of data that needs to be processed, resulting in faster query execution.
- Enhanced data filtering: Partitioning allows for efficient data filtering based on specific criteria or conditions. Since data is organized into partitions based on attributes, filtering operations can be performed directly on the relevant partitions, reducing the need to scan unnecessary data.
- Efficient data loading and unloading: Partitioning facilitates faster data loading and unloading processes. Instead of loading or unloading the entire dataset, operations can be performed on a partition-by-partition basis, improving data transfer speeds and reducing the time required for data ingestion or extraction.
- Better data maintenance: Partitioning can simplify data maintenance tasks. For example, partition-level operations such as archival, backup, or data lifecycle management can be performed selectively on specific partitions, allowing for more granular control and efficient data management.
- Optimal resource utilization: Partitioning enables workload distribution across multiple processing resources or nodes. By distributing data partitions across available resources, the system can leverage parallelism and optimize resource utilization, resulting in faster data processing and improved scalability.
- Improved data availability and recovery: Partitioning can enhance data availability and recovery capabilities. In case of failures or data corruption, partition-level recovery or restoration can be performed, reducing the impact and time required for data restoration.
The effectiveness of data partitioning depends on factors such as data distribution, query patterns, and the specific data processing framework or database being used. Appropriate partitioning strategies, such as choosing the right partitioning keys or criteria, are essential to achieve optimal data processing efficiency and query performance.
10. Explain the concept of data lineage and its significance in a data engineering context.
Data lineage is the process of traceability and accountability of all activities that occur on an organization’s data. Data lineage traces each individual data item through each stage and component of the data processing flow from its origin, such as a database, to its consumption, such as a self-service analytics dashboard. This involves understanding how each step in the process contributes to the final product.
Data lineage is important in a data engineering context since it provides visibility into the data flow and enhances traceability, auditing, and compliance processes. Data lineage helps identify data sets that are connected and dependent on each other and data points necessary for business decisions. This helps prevent errors in the data engineering process and allows for easier and faster debugging. It also increases trust in the data being used, and any changes to the data flow can be quickly identified and rectified.


Data engineer behavioral interview questions and answers
As the demand for skilled data engineers continues to rise, it becomes crucial for candidates to excel in behavioral interviews that assess their technical knowledge, problem-solving abilities, and interpersonal skills. Let’s explore a collection of common behavioral interview questions for data engineers, along with sample answers that can help aspiring candidates prepare effectively and showcase their expertise in the field.
11. Describe a situation where you had to collaborate with cross-functional teams to deliver a data engineering project. How did you ensure effective communication and collaboration?
A sample answer:
“In a recent data engineering project, I collaborated with both the data science and software engineering teams. To ensure effective communication and collaboration, I initiated regular meetings to align our goals and clarify project requirements. I made sure to actively listen to everyone's perspectives and concerns and encourage open dialogue. Additionally, I created a shared project management platform where we could track progress, assign tasks, and discuss any challenges or dependencies. By maintaining clear and transparent communication channels, fostering a collaborative environment, and emphasizing the importance of cross-functional teamwork, we were able to successfully deliver the project on time and exceed expectations.”
12. Describe a time when you had to troubleshoot and resolve a critical data pipeline issue under time pressure. How did you handle the situation?
A sample answer:
“In a previous role, we encountered a sudden failure in a critical data pipeline that resulted in a significant data backlog. With time being of the essence, I immediately initiated a root cause analysis to identify the issue. I worked closely with the operations team to investigate system logs, monitored network traffic, and examined database connections. Through thorough analysis, we discovered that the failure was caused by a faulty network switch. To quickly resolve the issue, I coordinated with the network team to replace the malfunctioning switch and reroute traffic to a backup path. Simultaneously, I implemented temporary measures to prioritize and process the accumulated data backlog. By demonstrating strong problem-solving skills, coordinating effectively with different teams, and implementing swift remedial actions, we successfully resolved the issue and minimized data processing disruptions.”
Apply for remote data engineer jobs at EPAM Anywhere
If you're a data engineer seeking remote opportunities, look no further than EPAM Anywhere. EPAM Anywhere offers exciting remote positions for talented data engineers, allowing you to work from your location and build a remote-first career in tech. With our global presence, you'll have the opportunity to collaborate with renowned professionals on top projects while enjoying the flexibility of remote work.

As Chief Editor, Darya works with our top technical and career experts at EPAM Anywhere to share their insights with our global audience. With 12+ years in digital communications, she’s happy to help job seekers make the best of remote work opportunities and build a fulfilling career in tech.
As Chief Editor, Darya works with our top technical and career experts at EPAM Anywhere to share their insights with our global audience. With 12+ years in digital communications, she’s happy to help job seekers make the best of remote work opportunities and build a fulfilling career in tech.
Explore our Editorial Policy to learn more about our standards for content creation.
read more